A projekt, mint egy elszabadult úthenger, száguldott tovább. Tegnap jutottunk el addig a lépésig, hogy növeljük a levéltovábbítás rendelkezésreállását, meg elosszuk a terhelést. Azaz berakjunk egy második HUB Transport szervert a meglévő mellé.
Hogy érthetőbb legyen az írás, összedobtam egy skiccet.
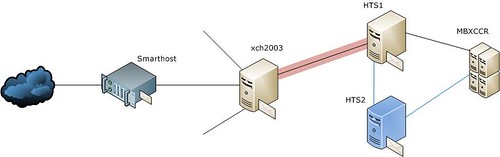
Azaz van jobb oldalon egy CCR MBX szerver, előtte a HTS szerverek. A piros vastag vonal jelöli az Exchange 2007 – Exchange 2003 közötti routing group konnektort. Baloldalt pedig egy smarhost tartja a kapcsolatot a nettel. (A levegőben lógó vonalak egyéb, belső levelezési irányok.)
Kékkel jelöltem az újonnan berakott HTS szervert. HTS1 és HTS2 teljesen megegyező virtuális gépek.
Hogyan lesz ebből érdekes cikk? Hiszen a felállás egyszerű, mint a faék. Működnie kell, oszt jól van.
Csakhogy nem működött.
Abban a pillanatban, ahogy beraktam HTS2-t, bedőlt a kifelé menő levelezés – legalábbis a levelek jó része nem ment ki. A HTS2-n lévő várakozási sorokban pedig elkezdtek gyűlni a levelek. Egész pontosan így hívták az érintett queue-kat:
- HTS1-xch2003
- HTS1
A queue viewer azt mondta, hogy a legutolsó hibaüzenet ez volt:
451 4.4.0 Primary Target IP Address responded with :” 451 5.7.3 Cannot achieve exchange server authentication.” Attempted failover to alternate host but that did not succeed.Either there are no alternate hosts or delivery failed to all alternate hosts.”
Target IP. Valószínűleg a fejlesztőknek leesett volna a karikagyűrű az ujjukról, ha ki is írták volna, hogy jelen esetben ki is volt az a target, aki visszaröffent? HTS1? Xch2003? A smarthost?
Na, mindegy. Kezdjük el összerakni a kirakós játékot. A Google szerint ilyen probléma akkor van, ha Exchange 2007 szervert kötünk össze Exchange 2003 szerverrel (eddig jó) és a 2003-ason nincs engedélyezve az integrated autentikáció. Megnéztem, engedélyezve volt. Innentől a Google felejtős, más találat nem volt. Kénytelen voltam az eszemet használni.
A queue-k csak a HTS2-n látszottak. Viszont az első queue neve gyanúsan ugyanaz volt, mint az RGC-é. Lehetséges, hogy nem is az xch2003-2007 határon van a probléma? Mit is tanultunk az Exchange 2007 routolásról? Például azt, hogy queue at point of failure – azaz szállítási hiba esetén a levelek azon a szerveren várakoznak, amelyik legközelebb van a szakadáshoz.
Azaz nem az xch2003 és a HTS1 között van a hiba, hanem már a HTS1 előtt.
Nadehát… mi lehet itt? A közvetlenül egymás mellé bedugott két Exchange 2007 HTS szerver nem tud kommunikálni egymással?
Mindenesetre gyorsan lekötöztem az RSG lábát a HTS2-höz is (ez már nincs a rajzon), így a levelek nagy része huss, kirepült. De ettől a probléma nem oldódott meg. Hiszen még élt a HTS1 queue, és álltak ebben is levelek.
Jogos a kérdés, hogy ezek vajon milyen levelek lehettek? Milyen levelek azok, melyek a fenti rendszerben a CCR-en keletkeztek, a HTS2 átvette továbbításra, majd továbbküldte a HTS1-nek… hogy az továbbítsa vissza cuccot a CCR-nek. Elég bizarr kör, nemde?
Mit tanultunk még az Exchange 2007 routolásáról? Delayed fan out – azaz ha egy levélnek több címzettje van, akkor addig a pontig, amíg a levelek együtt mennek, lejátszódik egy direct relay, majd onnan megy minden csomag a maga útjára, további direct relay-vel. Azaz a vizsgált várakozási sorban azok a levelek álltak, melyeket olyan levelezési csoportoknak küldtek, amelyiknek volt tagja a CCR-en, de volt tagja vagy a külvilágban, vagy az xch2003 rendszerben… vagy bármelyik más célpontban. Ekkor lett volna egy direct relay a HTS1-re, majd onnan a CCR-en lévő postafiókoknak ment volna vissza is a levél.
De nem ment. Illetve…
Nyilván, telnet. Nyilván ‘ismeretlen parancs’ választ kaptam. Hogy mekkora biztonsági fenyegetést jelent Windows 2008 szerveren a default telepített telnet kliens… nem tudom. De én már sokadszor futok bele abba, hogy nincs… és már majdnem annyira frusztrál, mint az UAC.
Na, mindegy. Telepítve. Aztán boldogan telnetelgettem. És sikeresen. HTS2-n belépve, HTS1-re telnetelve, minden irányban elmentek a levelek. Csak a queue-ból nem ürültek.
Itt már kezdtem ingerült lenni.
Nézzünk már egy smtp logot. Hol is van? Az Exchange könyvtárban lévő smtpout könyvtár üres. Jó, akkor kapcsoljuk be az smtp logolást. Hol is kell?
Azt írják, hogy a logolást a send konnektoron kell beállítani.
Kérdés: hol van itt send konnektor? Egyáltalán, ki csinált itt send konnectort? Mert én biztosan nem.
Nem is kellett. Ugyanis amikor beteszünk egy AD site-ra egy második HTS szervert, automatikusan létrejön egy send konnektor a kettő között.
Megint tanulunk. Milyen send konnektorok is léteznek?
- Explicit: Határozott ráutaló magatartással mi gyártjuk le, vagy a konzolból, vagy a shellből a new-sendconnector paranccsal. Jellegzetessége, hogy látszik: azaz mindkét menedzsment felületről nézegethetjük, konfigurálhatjuk.
- Semi-explicit: Ugyan automatikusan keletkeznek, de a konnektorok látszódnak, konfigurálhatók. Tipikusan ilyenek az Edge szerver beállításakor az Edge-HTS send konnektorok.
- Implicit: Automatikusan keletkeznek, nem látszanak, nem hozzáférhetők. Ha nem olvasgatnánk minden szabad percünkben Exchange szakkönyveket, nem is tudnánk róla, hogy léteznek.
Nyilván itt a legutolsóról van szó. Érezzük a bukfencet? Hogyan állítsunk be logolást egy olyan konnektorra, amelyhez semmi hozzáférésünk sincs? Marha egyszerű. Mint a viccben: rostáljuk át a sivatagot és ami fentmarad a rácson, az az oroszlán. Az alábbi írás szerint a következő parancsot kell kiadnunk, ha intra-organization send konnektort akarunk logoltatni:
Set-TransportServer “HTS2” -IntraOrgProtocolLoggingLevel Verbose
Ha kiadjuk… ugyanazt a kövér syntax errort kapjuk, mint amilyent én kaptam. A KB cikk ugyanis hibás. Kérjük le a get-help set-transportserver -full paranccsal a paraméterek listáját – és láthatjuk, hogy a helyes paraméter az -IntraOrgConnectorProtocolLoggingLevel. Ja, és ne lepődjünk meg, ha kigördül a képernyőről a szöveg. Nálam az EMS puffere 999 sor (több nem lehet), ebbe a paraméterlistának kábé a fele fért bele.
Viszont azt gondolom nem kell magyarázni, mi is történik. Azt mondtuk, hogy te, kedves HUB Transport szerver, logoljad lécci az összes send konnektorodat. És az összesben már benne van a szupertitkos is.
Transport szerver újraindít, ekkor ugye kénytelen megabajgatni a beragadt várakozási sort. Végre van log is. De milyen furcsa! HTS2 beehlózik HTS1-hez. HTS1 elsorolja, milyen kunsztokat tud. Majd páros lábbal kirúgja HTS2-t.
?
Gondolom, már hiányérzeted van. Miért nem ír ez a fazon a receive konnektorokról? Ordít, hogy ott lesz a hiba.
Először én is így gondoltam. Átnéztem többször is, az összeset.
– Milyen összeset? – kérdezhetnéd.
– Hát, a gyárit, meg a barkácsoltat – válaszolnám.
Miért is kell barkácsolni? Close Relay. Az ember a default (server) receive konnektoron állítja be, hogy a szóbajöhető IP tartományból mindenki bejöhessen, mindenféle autentikációt használhasson – eltekintve az anonymous hozzáféréstől. Emellett célszerű gyártani egy relay receive konnektort is, melyet úgy állítunk be, hogy ne kérjen autentikációt és engedélyezze az anonymous hozzáférést. De itt, a network fülön csak – és szigorúan csak – azokat a hostokat engedjük, melyek számára engedélyezzük a relay-t… és amelyek annyira rendszeridegenek, hogy kizárt velük minden együttműködés. (Tudom, ne mondjuk soha azt, hogy kizárt… mondjuk helyette azt, hogy egyik oldal sem akar annyi energiát beleölni a mutatványba, hogy összehozzunk egy tisztességes autentikációt. Inkább megbízunk egymásban.)
Nos, receive konnektorok többször is átnézve, ránézésre minden rendben. Pedig az eddigi nyomozásból 110 százalékra tudjuk, hogy kizárólag csak itt lehet a hiba.
Kiváncsiságból kikapcsoltam a relay konnektort. Abban a pillanatban kirepült az összes levél a queue-ból.
Oké. Akkor eddig megvolnánk. Idő? Még ma van. Igaz, éppenhogy csak. Mindenesetre a szemem már annyira kifolyt a helyéről, hogy amikor telefonálgatnom kellett, folyamatosan zárva tartottam. Addig is pihent.
Gyors mérleg: queue üres. Megvan a bűnös. Én viszont már használhatatlan vagyok. HTS2 lekapcsol, relay receive konnektor visszakapcsol. Ezzel el tud zakatolni az ügyfél… aztán holnap is nap lesz.
Hátha megálmodom, mi lehet a baj.
Nem hiszed el, megálmodtam.
Reggel felkeltem… és fogmosás közben lepörögtek előttem a konnektorokban lévő network listák. Bakker, a HTS2 mindkét receive konnektor szkópjában szerepel! Márpedig a relay konnektor a szigorúbb, tehát az lesz rá érvényes… ekkor viszont nem lesz engedélyezve számára az Exchange autentikáció!
Napközben volt éppen elég más dolgom is, az összeszedettség szobrát sem rólam mintázták volna, de délutánra összevakartam magam. (Két redbull, meg egy vizespohár kávé.) Háromkor bejelentettem, hogy éles teszt. A kollégáimnak elszürkült az arcuk. Szerettek volna otthon éjszakázni.
Lecsökkentettem azt az IP tartományt a relay receive konnektoron, mely magába foglalta a HTS2-t is. Majd bekapcsoltuk a HTS2-t. Queue viewer… és gyönyörűen üres.
– Na látjátok, nem kell beszarni – nyugtatgattam a többieket – megy ez.
Már majdnem pezsgőt bontottunk, amikor megjelent az első kézbesítetlen levél a HTS1 queue-ban.
– Miaf? – néztem bambán. Hiszen annyira biztos voltam az elméletemben.
– Figyelj, még egy olyan délutánt nem engedhetünk meg magunknak, mint tegnap – figyelmeztettek.
– Oké, tíz levélig elmegyünk. Ha addig nem tudom megoldani, akkor letiltjuk a relay konnektort és leállítjuk a HTS2-t.
Körülbelül hat levélnél jártunk, amikorra kiszúrtam, hogy a relay receive konnektor network listájában direktben is fel volt véve a HTS2 IP címe. Nyilván a tegnap esti eszetlen rodeó egyik fázisában tehettem egy bátortalan kisérletet. Gyorsan töröltem, pár perc várakozás – és a queue kiürült.
Győzelem. Ugyan vártunk még egy félórát, mielőtt megfújtuk volna a harsonákat – de én már rögtön biztos voltam a győzelemben: hiszen kiürült a feltorlódott queue. Ez már nem fog még egyszer feltorlódni.
Hátravolt még a nyomozás: hogyan történhetett meg egy ilyen félrekonfigurálás?
Ezt is megtaláltam. Nem voltam boldog. Én gépeltem el… méghozzá az implementációs tervben. Egy A4-es oldal méretű táblázatban voltak felsorolva azok az IP címek, akiknek engedélyezve volt a relay. (Az értékeket az Exchange 2003 rendszerből kellett átvinni a 2007-be.)
A táblázat valahogy így nézett ki (az értékek nem valósak):
- 192.168.100.0/24
- 192.168.101.0/24
- 192.168.102.0/24
- Meg vagy hatvan szóló IP cím
A harmadik helyen a jó érték az lett volna, hogy 192.168.102.0/25… azaz csak a tartomány alsó felének volt engedélyezve a relay. A HTS2 pedig ugyanezen tartomány felső felében volt.
És amennyire precíz vagyok, az implementáció során pontosan ezt a táblázatot pötyögtem be – így került bele mindkét konnektor szkópjába a HTS2.
Shame on me.
Tudom, a következőket fel lehet fogni egyfajta racionalizálásnak is… de ez nem fog visszatartani attól, hogy elmélkedjek egy kicsit az eseten.
Jó-e egy ilyen hiba a projektben? Dühöngjünk-e miatta? Vagy – és most nagyon meredeket mondok – örüljünk-e egy ilyen hibának?
Én az utóbbira szavazok. És nem csak azért, mert pontosan ezt állítja a talán legkedvesebb könyvemben – A zen és a motorkerékpár ápolásának művészete – Robert Pirsig is… hanem azért, mert én magam is ebben hiszek. Ha belefutsz egy hibába, és ellövöd rá az összes töltényedet, de a hiba makacsul megmarad… akkor ujjonganod kell. Mert a hiba rá fog kényszeríteni arra, hogy átlépd a határaidat… hogy olyan fegyvereket, olyan harcmodort találj ki, melyeket korábban nem ismertél. Az ilyen hiba tágítja a gondolkodásod horizontját.
Most például a valóságban is találkoztunk olyan – korábban csak elméletből ismert – jelenségekkel, mint a ‘queue at point of failure’ vagy a ‘delayed fan out’… megtanultuk, hogyan lehet send és receive konnektorokat logolni… és egyáltalán, elmélyedtünk a levéltovábbítás módjában, beleégettük a gondolkodásunkba a folyamat felépítését.
Innentől jobban fogjuk érteni, mi is történik a mélyben.
Recent Comments