Nagyjából éppen a bokáig érő lószarban sárban cuppogtam Moritzburg környékén, amikor egyik ügyfelünk nem kicsit bonyolult Exchange mailbox szervere úgy döntött, hogy torkonszúrja magát. No nem nagyon, de két mailbox adatbázis és a public folder adatbázis leállt. Kolléga rávetődött az incidensre. Hamar rájött, hogy a leállást az okozta, hogy betelt egy log partíció. Egy olyan partíció, ahová ez a 3 adatbázis dolgozott.
Kitérő:
Igen, ilyet teljesítményproblémák miatt nem szoktak csinálni. Csakhogy egész egyszerűen az ügyfélnél annyi adatbázis van, hogy nincs annyi betű az angol ABC-ben, hogy minden log könyvtárhoz külön partíciót rendeljünk. Így a 3 legritkábban használt, legkisebb adatbázis log fájljait egy partícióra tettük.
Nos, a két pici mailbox adatbázisból az egyik bevadult. Nem, nem a korábbi bevadulás, ennek üzleti okai voltak. A vadulás miatt elszabadultak a logfájlok, betelt a partíció, méghozzá olyan gyorsan, hogy a riasztás után már cselekedni sem maradt időnk – aztán leállt mindhárom adatbázis.
Kitérő:
Maga az Exchange mailbox rendszer a következőképpen nézett ki: CCR rendszer egy aktív és egy passzív node-dal, melyhez kapcsolódott egy SCR rendszer egy passzív node-dal.
Tehát ez volt a játszótér és adott volt a feladat. Az ügyfél nyilván ki volt kattanva, hiszen mi az, hogy egy ilyen bonyolult cluster elérhetetlenné válik – és természetesen azt várta el, hogy minél hamarabb megint elérhetőek legyenek az adatbázisok. Kolléga fogta, és a CCR mindkét node-ján elmásolta ugyanazt a nagy kupac régi – ergo már biztosan rájátszott – logot mind a public folder, mind a bevadult adatbázis logkönyvtárából, felmountolta az adatbázisokat és minden be is indult szépen. Az adatbázisok működtek, sőt, a konzol alapján a log replikáció is egészséges volt. Problem solved.
Egészen addig mindenki nyugodt volt, amíg el nem érkezett a mentés ideje. De elérkezett. Le is ment – majdnem minden adatbázisra. Egy, csak egy szaladt hibára, az a bizonyos vad adatbázis. Mely ugye nem véletlenül vadult be, a hirtelen megnövekedett üzleti igények okozták a hízást – azaz meglehetősen fontos adatok kerültek az adatbázisba.
Kolléga még megnézte az eseutil /mh paranccsal, hogy konkrétan milyen log fájlok hiányoznak a passzív node-on – de a válasz az volt, hogy semmi. Rá lett küldve egy reseed (update-storagegroupcopy), de csak annyit csinált, hogy a passzív node-on kiürült a logkönyvtár.
Ekkor érkeztem vissza szabadságról és rögtön meg is kaptam a feladatot.
Helyzetfelmérés:
- Az adatbázis megy, ránézésre a log replikáció egészséges, az ügyfél nyugodt.
- Ezzel szemben az aktív node-on rengeteg log van, a passzív node-on egy sem. Az adatbázisok azonos méretűek, azaz a reseeding sikerült.
- Az SCR node-on az a bizonyos partíció fullon volt, a replikáció az említett adatbázisokon állt. Szemmel láthatóan az SCR-rel senki sem foglalkozott.
- Viszont mivel nem sikerült a mentés, az aktív node-on pár óra múlva megint elfogy a hely, szóval nagyon gyorsan ki kell találni valamit.
Ergo egyfelől meg kellett akadályoznom az újabb leállást, másfelől össze kellett kötözgetnem a szálakat, mert itt valami nagyon félrement.
A feladat első része volt az egyszerűbb. Kerestem egy üres partíciót (későbbi fejlesztésekre volt is félrerakva egy, de a későbbi szó pont azt jelenti ugye, hogy nem mostani), majd átirányítottam ide a logolást.
Ránézésre olyan egyszerűnek és logikusnak tűnik – de nem az. Nem véletlen, hogy a kollégám sem így próbálkozott. Neki ugyanis sietnie kellett.
Első lépésben ugyanis suspendbe kell rakni a log replikációt. Ez még nem is fáj.
Második lépésben dismountolni kell az adatbázist, ráadásul bizonytalan ideig. Ez már fájt az ügyfélnek, nem is mentek bele szó nélkül. Amikor közöltem velük, hogy ez van, törődjenek bele, nincs más lehetőség, rögtön jöttek, hogy bezzeg a kollégám meg tudta oldani máshogyan. Na, ez a szakma kellemetlen része. Elmagyarázni az ügyfélnek a szakmai finomságokat, úgy, hogy közben a mundér becsületét is megvédjük. Végül azért sikerült tisztáznom, hogy a múltkori az egy gyors, ideiglenes megoldás volt, én viszont már a végleges megoldáson dolgozom.
Ha ezzel megvagyunk, akkor jön a move-storagegrouppath parancs, valahogy így:
move-StorageGroupPath -Identity ‘adatbázis‘ -LogFolderPath ‘ujlogkonyvtar‘ -SystemFolderPath ‘ujsystemkonyvtar‘ -configurationonly
Vagy hogy érthetőbb legyen, konkrét példával:
move-StorageGroupPath -Identity ‘server\vad-adatbazis’ -LogFolderPath ‘Z:\exchsrvr\log’ -SystemFolderPath ‘Z:\exchsrvr\log’ -configurationonly
Határozottan felhívom a figyelmet a configurationonly paraméterre! CCR környezetben a logkönyvtárt ugyanis nem lehet csak úgy átrakni. A parancs hatására a következők történnek:
- Az AD konfigurációs névterében az érintett storage group tulajdonságainál átíródnak a log, illetve system könyvtárak útvonalai.
- Emellett az új könyvtár (z:\exchsrvr\log) meg lesz osztva, méghozzá egy GUID névvel. Ha visszanézzük, akkor ez a GUID a storage group azonosítója. A megfelelő jogosultságokat szintén beállítja a parancs.
Végül ha ezen túlvagyunk, akkor manuálisan átmásoljuk a lecsatolt adatbázis log és system fájljait a régi helyről az újra, majd felmountoljuk az adatbázist. Ha nem rontottunk semmit el, akkor el is indul.
Látjuk, az időbeli bizonytalanságot a logfájlok másolása jelenti. Viszont amíg a másolás folyik, addig szét is tud replikálódni a címtárban a változás.
Ezzel a sürgős résszel meg is volnánk, jöhet a kötözgetés.
A biztonság kedvéért ráküldtem én is egy reseedet. Hátha apucitól jobban elfogadja. De semmi. Vágjunk mélyebbre. Újraindítottam a passzív node-on a replikációs szolgáltatást.
És végre történt valami. A replikáció státusza elmozdult az egészséges állapotból. Initializing. A végtelenségig. Vártam rá egy kicsit, aztán eluntam. Ennél még a kamu egészséges visszajelzés is jobb volt. Újabb reseed.
Jobb híján nézelődtem, gondolkodtam. A log könyvtár átmozgatása rendberakta az SCR-t, tökéletesen működik. Azért ez is valami: van egy aktív CCR node-om és egy passzív SCR node-om.
Aztán egy kellemetlen gondolat. Eddig azt mondtam, hogy a logfájlok másolása sértett meg valami ismeretlen dolgot az Exchange rejtett mélységeinek szövetében. De akkor a public folder adatbázisok logshipping folyamatának sem kellene működnie. Aztán mégis működik.
Hjaj. De bonyolult az élet.
Get-storagegroupcopystatus. Mindenki healthy. Egészségükre. Aztán hoppá. A CopyQueueLength értéke a vad adatbázisnál 14234. Mit ír erről a manuál? Azt, hogy ha az értéke nagyobb 3-nál, akkor baj van. Hmm. Ide azért most nem kell fejszámolóművész, itt baj van.
Test-replicationhealth. Minden passed – kivéve a vad adatbázis copy queue értéke. Az viszont nagyon nem.
További nézegetés. Hoppá. Nincs a passzív node-on edb.chk. Ezt azért volt nehéz észrevenni, mert abszolút nincs semmi más sem a könyvtárban. Ez azért magyarázza, miért nem ment le a mentés. (Akinek újdonság lenne: az Exchange az edb.chk fájlba írja, melyik lognál indult a mentés, azaz a mentés után meddig kell törölni a logokat.) Lehetséges, hogy nem csak a backup használja ezt, hanem a log replikáció is? Nagyon lehet, hiszen egy normális reseed úgy indul, hogy törli az edb.chk-t és az adatbázist.
Akkor lehet, hogy nem is jó a látszólag jó reseed?
Mint az ínyenc, aki a legfinomabb falatokat a végére hagyja, én is elővettem végül az event logot. Volt is benne érdekesség.
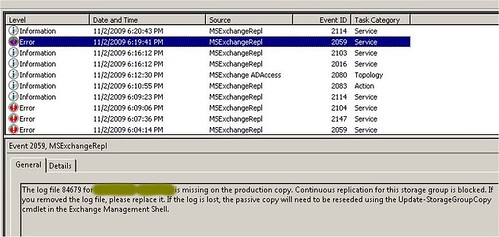
Ez legalább világos beszéd, végre. Habár az eseutil /mh szerint nem hiányzik neki logfájl, de az eventlog szerint mégis hiányzik a 84679-es számú. (Azért ezen ne lepődjünk meg. Az eseutil csak az adatbázis épségével foglalkozik – és az adatbázisok tökéletesen jók. Itt a logshipping szakadt össze, de ahhoz az eseutil meg nem ért.) Természetesen ilyen nevű logfájl nincsen. De ennyi szívás után az ember már csak legyint és átszámol hexába: 14AC7. Ilyen nevű log már lehet. De hol? Hát például a kolléga által félrementett logok között, melyeket szerencsére nem töröltünk.
Mi lenne, ha bemásolnám az aktív node logkönyvtárába?
Bemásoltam. Egy perc focilabda rugdosás (az új irodámban nincs darts tábla) – és ott van a log a passzív node-on is. Vérszem. Az az, amit kaptam. Bemásoltam a sorban következő 10 logot az aktív node-ra. Egy percen belül megjelentek a passzív node-on is. Ujjé. Elkezdtem név alapján bogarászni az éles log könyvtárat és a mentett logok könyvtárát. Úgy tűnik, hogy az egyik a zsák, a másik meg a foltja. Ha a félremásolt logokat átmásolnám az éles logkönyvtárba, akkor zárt lenne a sor.
Persze ehhez több hely kell.
Újabb telefon az ügyfélnek. Leállnánk pár percre, ugye nem baj? Ügyfél füle egy kicsit rángatózik.
Átmásoltam a logokat egy nagyobb partícióra. (Igen, ez már adatbázispartíció volt. De csak a mentésig lesznek itt a logok, addig meg kibírják.)
Utána pedig megtörtént a nagy családegyesítés. Elvonultam gyakorolni a külső csavarást a nyomtató asztalának lábai közé. 20 perc műlva néztem vissza – és a logok szorgalmasan másolódtak át a passzív node-ra. Remek.
Legyen teljes a győzelem: újabb get-storagegroupcopystatus. A CopyQueueLength értéke szépen le is csökkent… de miaf… elkezdett növekedni a ReplayQueueLength értéke. Ugyan – hessegettem el a kellemetlen gondolatot – ez most kapott hirtelen 14000 logot, persze, hogy nem tudja ilyen tempóban rájátszani. Hagyjuk békén, holnap reggel majd meglátjuk, mi lesz a vége.
Eljött a holnap reggel. A győzelem érzésével gépeltem be a jó öreg get-storagegroupcopystaus parancsot – és a ReplayQueueLength értéke 500 körül volt. Az első gondolatom rögtön az volt: miért? A nullát el tudtam volna fogadni. A 14000 körüli értéket szintén. De miért pont 500?
A magyarázat gyorsan jött. Konzol, gyors vizuális pásztázás: a vad adatbázisnál a logshipping státusza failed. Aha. 500-nál besokkalt, aztán azóta coki.
Hát. Tulajdonképpen előrébb vagyunk. De a beteg még mindig kómában fekszik.
Most már nem álltam neki ködöt rágni, mentem egyből az eventlogba.
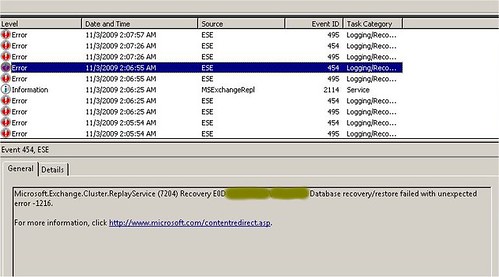
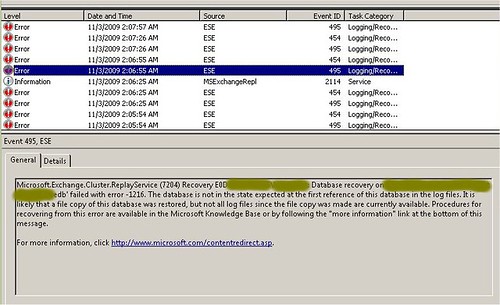
Keressünk rá a hibakódra. Azt írja, hogy a 1216 azt jelenti, hiányzik néhány tranzakciós log. Kérdezzem le az eseutil /mh paranccsal, mely logok hiányoznak. Lekérdeztem. Semmilyen log sem hiányzik.
Bakker. Mégis köd. Azért ez már kezd bizarrá válni: egyfelől azt mondja, hiányzik neki x darab log, ahhoz, hogy rájátssza végre az összes logot arra az adatbázisra, amelyikre már jó egy hete rá van játszva az összes log – másfelől pedig konkrét kérdésre azt mondja, hogy nem is hiányzik neki egy log sem.
Csak éppen nem indul el a rájátszás.
Ekkor már teli csőrrel gyakoroltam a védhetetlen bombákat a szerverszoba ajtajára.
Végül visszadaráltam az elejére. Emberek, végülis… már van edb.chk fájlunk a passzív node-on. Ez jó hír.
Töröljük gyorsan le. Azaz küldjünk rá egy reseed-et. Mert mi van, ha az a baj, hogy az adatbázis – amelyikre már rá van játszva minden log – nincs szinkronban a logkönyvtárban lévő edb.chk-val, mely még csak nemrég jött létre, a replikáció befejeztével. A reseed ugyanis törli mindkettőt, majd újra létrehozza, immár szinkronban.
És tényleg.
A ReplayQueueLength értéke egyből lenullázódott, a logshipping meggyógyult. A pezsgőbontással vártam még tíz percet, mert ez a nyomorult replikáció képes megint elromlani – de nem.
Tanulság:
- Amíg elő nem varázsolom valahonnan a hiányzó logokat, addig felesleges a reseed. Nincs értelme. Nincs edb.chk.
- Ha megvannak a logfájlok, akkor vissza kell másolni az aktívra, a logshipping beindul, legyártódik az edb.chk. Ekkor viszont kötelező a reseed, mert ez hozza összhangba a két node-ot.
Végül egy kényelmetlen gondolat:
És akkor mi van, ha közben töröltem a logokat?
Nos, végső esetben az SCR-en ott kellett lenniük.
De mi van, ha onnan is töröltük? Gáz.
Szóval óvatosan azzal a közvetlen logpiszkálással.
ps.
Elkiabáltam. Utólag derült ki, hogy az SCR node-on sem megy a rájátszás, ott is újra kellett seedelni az adatbázist és a logokat.
Recent Comments