Már korábban írtam róla, hogy elkövettem egy ingyenes vírusirtót az Exchange 2007-hez. Most elkészült ennek az Exchange 2003-al vagy IIS SMTP szerverrel használható változata. Mind a kettő megtalálható a http://www.clamagent.org -on.
Tag: exchange 2003
Elérhetetlen public folderek
Már teljesen beletörődtem.
Közbevetőleges kérdés: mi a különbség egy linux és egy microsoft admin között? Az, hogy az utóbbinak megadatott a hit lehetősége. A linux admin ugyanis _tudja_, mi történik a rendszerében.
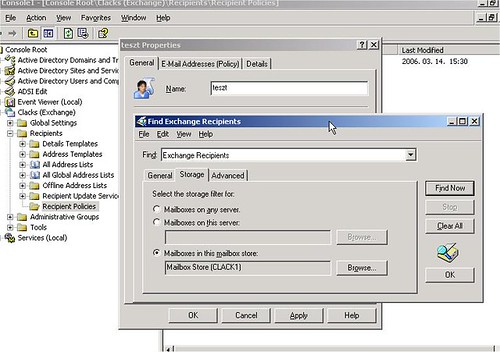
No, szóval a magam részéről megszoktam már, hogy amikor feltelepítek egy Exchange 2003 szervert, egy ideig el tudom érni ESM-ből az Administrative Groups / admgroup / Folders alatt a public foldereket. Aztán egy idő után – talán miután beleszokott a szerver az organizációba – az elérés ellehetetlenül. Feljön egy hibaüzenet:
The token supplied to the function is invalid
ID. no: 80090308
Exchange System Manager
És ennyi.
Mondjuk, soha nem zokogtam emiatt tele a kispárnámat, általában mindig volt olyan Exchange szerver, amelyikről ment.
Ma egész véletlenül kiderült, mi is történik ilyenkor.
Ki kellett cserélnünk egy üzemelő Exchange szervert. Beraktuk az újat. A postafiókok elkezdtek vándorolni. A kollégák éppen a public foldereken állítgatták a replikákat, amikor én nekiálltam befaragni az owá-t. Felraktam egy tanusítványt, majd bekattintottam a default web site-on, hogy innentől mindenki szigorúan SSL-t kell használjon. IIS restart.
Abban a pillanatban jött egy ordítás a szomszéd szobából:
– JoeP, nem tudom, mit csináltál, de azonnal csináld vissza!
Természetesen nem csináltam vissza. IIS adminból végigmentem egyenként a virtuális site-okon és próbáltam behatárolni, konkrétan melyik site is az, mely nem lehet SSL elérésű. Nem meglepetés, az Exadmin-nál borult a bili.
A továbbiakban már egyszerű volt, a default web site SSL nélküli lett, integrated autentikációval, az Exadmin szintén, a többi pedig basic, SSL-lel.
ps.
Azt tudtam, hogy Exchange 2007 alatt powershell cmdlet van a website-ok jogosultságának resetelésére. De mi van Exchange 2003 alatt? Utánanéztem. Nem örültem.
A recept a következő:
- Metabase backup.
- A default web site alól törölni az összes site-ot. (Szívhez kap, összerogy.)
- A Metabase-ből törölni az LM/DS2MB kulcsot. (Szigorúan Metabase Explorer.)
- Újraindítjuk a System Attendant szolgáltatást.
Akit mélyebben is érdekel a dolog, itt talál róla cikket, itt meg screencastot.
Az a szerencsétlen public folder…
Rájár a rúd, rendesen. Persze, igazából még a Microsoft se nagyon tudja, mit csináljon vele.
Amikor kijött az Exchange Server 2007, azt mondták, hogy már csak megtűrt lett szegény. Nem is kapott GUI-t, csak parancssort. Aztán felhorgadt a népharag, az Sp1-ben beépült az Exchange Management Console-ba. De mindig ott lógott fölötte Damoklész kardja, hogy majd az E14-ben, na ott már úgy ki lesz hajítva az udvarra, mint macskát anyagcserélni.
Ehhez képest tegnap jelent meg egy írás az Exchange blogon, mely teljes mellszélességgel kiáll a Public Folderek mellett. Hogy persze. Támogatjuk. De azért ismerkedjél bőszen a Sharepointtal, Kedves Rendszergazda.
Nem egyszerű helyzet.
De nem is erről akartam írni. Hanem arról, hogy mi is a helyzet a public folder referrals beállításokkal az Exchange 2007-ben. Azaz mennyire lesznek virulensek a public folder eléréseink.
Messziről fogok nekifutni. Egészen az Exchange 2000/3 termékvonaltól. Sőt.
A Public Folderek némileg egyedi figurák egy Exchange rendszerben. Van nekik adatbázisuk, a szokásos .edb formátumban. Meg lehet adni, mely szervereken legyenek. De nem csak adatból állnak, fontos komponensük a hierarchia is. Igen, a folderszerkezet. Ez, ha jobban megnézzük, egy halom pointerből áll, ezek mutatnak a bináris .edb fájl megfelelő pontjaira.
A lényeg az, hogy külön-külön élnek. A hierarchia egységes, organizáció szinten. De adat, az nem feltétlenül kell, hogy ott legyen minden szerveren.
Ismerkedjünk meg még a Routing Group fogalmával. Ez gyakorlatilag a Telephelyet jelenti, Exchange szlengben. A Routing Group Connector (RGC) pedig a kapcsolat közöttük – azaz a gyenge, vékony, lassú vonalakkal elválasztott hálózati entitások között.
Nézzünk egy példát. Az Outlook kliensemből létrehozok egy új Public Folder alfoldert valahol, jó mélyen a struktúrában. Hol is fog ez létrejönni? Természetesen annak a szervernek a Public Folder adatbázisában, amelyiken a postafiókom van. De az új alfolder a hierarchiában egyből megjelenik, látni fogják Alaszkától Hódmezővásárhelyig, mindenhol.
Mi történik, ha valaki le akarja kérni a tartalmát? Ez leginkább attól függ, hogy én, mint adminisztrátor, mit állítottam be. Ugyanis a Public Foldereknél alfolder szinten állíthatjuk, hogy mely szervereken legyen belőlük példány – és mikor történjen a példányok között a replikáció.
Mondjuk, az van beállítva, hogy ne replikálódjon sehová. Ebben az esetben azok járnak jól, akiknek ugyanazon a szerveren – nevezzük AL-nak – van a postafiókja, mint nekem. Ők egyből hozzá fognak férni az alfolder tartalmához. Mi van, ha valakinek az én Routing Groupomban lévő másik szerveren van a postafiókja? Hát, a hierarchiát látja… és az ún. public folder referral megadja, hogy mely szerverek PF adatbázisában létezik ennek az alfoldernek tartalma is. Tehát ők szépen átvándorolnak AL-hoz a tartalomért.
Mi van, ha valaki egy másik Routing Groupból akarja elérni az alfolderemet? Attól függ, mi van beállítva az RGC-n. Ugyanis létezik egy egyállású kapcsoló: Enabled/disabled public folder referral. Ha engedélyezve van, akkor a másik RG-ből eljönnek az én szerveremhez a tartalomért. Ha nincs, akkor hibaüzenetet kapnak vissza.
Jó ez? Nyilván nem – és az egésznek nem is az a célja, hogy hibaüzenetet kapjunk vissza.
Az elsődleges cél a gyenge vonal védelme az elárasztás ellen. Ha a vonal annyira nem gyenge, akkor engedélyezhetjük a PF referral-t, nem fogja padlóra küldeni, ha sokan lesznek kíváncsiak az alfolderemre. Ha viszont gyenge, akkor más stratégiát kell választanunk: azt mondjuk, hogy az alfolderemet lereplikáltatjuk egy másik szerverre a távoli RG-ban, méghozzá úgy, hogy csak este engedélyezünk replikációs forgalmat. Ekkor nyugodt szívvel tilthatjuk le a konnektoron a PF referral engedélyezést, hiszen minden lent lesz a lenti szerveren, ami kell. Nagyjából 24 órán belüli állapotban.
Így játszhattunk a régebbi Exchange rendszerekben. De mi van az Exchange 2007-ben? Hát, Routing Group, például nincs. Értelemszerűen RGC sincs. Akkor mi szabhat határt a public folder referralok burjánzásának?
Az RGC utódja. Az Active Directory IP Site link.
Tippeljünk!
Vajon az Active Directory IP Site linken tudunk-e Exchange Public Folder referral-t szabályozni?
- Nem. Hogyan nézne már az ki? AD linken Exchange tulajdonság? Olyan lenne, mint hajszárítóval permetezni.
- Miért ne? McGywer például egészen biztos, hogy permetezett már hajszárítóval. Gondoljunk csak bele, Exchange telepítés előtt lemegy egy sémamódosítás. Miért ne módosíthatná ez az IP Site link objektum definícióját úgy, hogy kiegészíti Exchange specifikus tulajdonsággal? Hiszen meg is teszi, ha EMS-ből lefuttatjuk a get-help set-adsitelink -detailed parancsot, láthatjuk, hogy az Active Directory IP Site linknek lett olyan tulajdonsága, hogy exchangecost, meg maxmessagesize.
Nos, melyikre tippelsz?
Sajnos az első. Elméletileg semmibe sem került volna felvenni egy igen/nem jellegű tulajdonságot az IP Site link objektumra – de nem tették. Csak saccolni tudok: tervezéskor nem is számoltak a Public Folderekkel. Csakhogy az élet máshogy döntött, Public Folderek bizony lesznek.
Korlátozhatatlanul.
Akkor mégis, mit tehetünk, hogy a Patagóniában létrehozott alfolder tartalmáért ne menjen el mindenki, aki pl. a calcutta-i részlegünknél dolgozik?
- Előremenekülünk. Ha eddig nem is volt a cégünknél megtervezett PF replikáció, akkor mostantól lesz. Megtervezzük, hogy minden Active Directory site-on, ahol van legalább egy Exchange 2007 szerver, melyiken legyenek ott a site leginkább használt Public Folderei. A replikációt mindenhol úgy időzítjük, hogy akkor történjen, amikor a vonalon alacsony a forgalom.
- Minden postafiók adatbázison van egy olyan beállítás, hogy azoknak, akiknek ebben az adatbázisban van a postafiókjuk, melyik legyen a default public folder adatbázisuk. Értelemszerűen ez mindenhol a Routing Group PF szerverére kell, hogy mutasson.
- Természetesen ezzel nem zártuk ki a Routing Group-ok közötti PF elérések forgalmát. De minimalizáltuk. Ha már megtiltani nem tudjuk.
Újabb Exchange esettanulmány
Ügyfél szeretné, ha meglévő Exchange 2003 Sp1 szervereire Sp2-t telepítenénk. Nem egy nagy dolog, mondhatnád. Csakhogy. A hálózatuk meglehetősen cifra, benne az Exchange organizáció szintúgy.
– Mekkora a valószínűsége, hogy félremegy a telepítés? – kérdezték.
– Minimális – válaszoltuk.
– És ha mégis félremegy, mekkora a kár?
– Nem vészes. Uninstall, oszt jól van.
– Akkor csináljátok.
Mindez volt tavaly ősszel. Ugyanis mielőtt nekiugrottunk volna, megnéztük, hogy tényleg van-e uninstall. Nem volt. Sőt. Azt mondta a silabusz, hogy ha egyszer felraktad, akkor az már odanőtt; nem szedheted le. Azaz ha félremegy a telepítés és azt hiszi az Exchange, hogy már fent van az Sp2, pedig igazából nem – nos, akkor elég hülyén járunk.
– Kedves Ügyfél, ezt benéztük. Nincs uninstall – kezdtük beadagolni a keserű pirulát.
– Akkor most mi lesz?
– Majd kitalálunk valamit.
– Az jó lesz, mert rollback elképzelés nélkül coki.
Azaz előállt a feladat: csináljuk meg azt, amit a Microsoft szerint nem lehet.
A legjobb módszer ilyenkor gondolkodni egy cseppet. Mit csinálhat egy service pack? Egész biztosan lecserél egy csomó binárist. Hol lehetnek ezek? A ‘program files/exchsrvr’ könyvtárban tuti, és tudjuk, hogy a mapi32.dll meg a system32-ben van, tehát ez a könyvtár is érintett. Mi lehet még? Hát, van még ugye a szerver konfiguráció – csakhogy ez nem az Exchange szerveren tárolódik, hanem a címtár konfigurációs névterében. Igen, abban amelyből egy darab van az egész erdőben. Séma? Nem, nem kell semmilyen séma preparáció, tehát ahhoz biztosan nem nyúl. Adatbázis? Nos, igen. Ez sarkalatos kérdés.
Azaz, ha vissza akarjuk állítani az esetlegesen félrement sp2 telepítés előtti állapotot, egész biztosan mentenünk kell a binárisokat és a konfigurációs névteret. A sémát biztosan nem kell, az adatbázisról – és hozzá kapcsolódóan a domain névtérről viszont nem tudunk semmit.
Teszt.
Virtuális tartományban virtuális Exchange szerver. Sp2 telepítés előtt összes Exchange szolgáltatás lestoppol, telepítés közben a másolandó fájlok útvonala meredten figyel. Az eredmény mindenképpen kellemes: a telepítőt nem zavarta, hogy nem éri el az adatbázisokat, ergo nem is bántja őket. A binárisoknál pedig csak a fenti két könyvtár érintett.
Körvonalazódik a megoldás. Hogy elkerüljük a felesleges replikációhullámokat, a félisten repadminnal leállítjuk az Exchange szerver logon szervereként szolgáló tartományvezérlőn a kifelé menő replikációt, csinálunk egy system state mentést a DC-n, csinálunk egy fájl szintű mentést az Exchange szerveren, majd jöhet a service pack. Hiba esetén visszatesszük a binárisokat, egy non-authoritative restore a lezárt DC-n – és kezdhetjük előlről.
Újabb teszt.
Ilyenkor jön jól a virtuális környezet, ugyanis az előző virtuális tartomány gépeit előrelátóan elmentettem, még a kísérlet előtt.
Replikáció leáll, sp2 felmegy. Nézzük, mit látunk? Nézni nézzük, de nem hisszük – telepítés után az ESM azt mondja, hogy továbbra is csak az SP1 van fent. ADSIEdit-tel megnéztem a tartományvezérlőket – és ledöbbentem. A telepítő nem a logon szerveren tárolt címtáradatbázis konfigurációs névterébe írt, hanem egy éppen arra járó kósza tartományvezérlő adatbázisába. Visszakeresni viszont a logon szerveren keresett. A replikáció meg ugye fejbe volt csapva.
Azannya. Akkor az izolációnak lőttek. Szerencsére létezik fa/objektum szintre korlátozható autoritatív visszaállítás is, amelynek tulajdonképpen mindegy, mit történt a többi tartományvezérlőn – csak éppen így majd lesz két erős replikációhullám az erdőben.
Végső teszt.
- Az összes Exchange szolgáltatás leállít.
- Az összes virnyákölő szolgáltatás leállít.
- Mentés az Exchange szerveren a fenti két könyvtárból.
- System state mentés egy közeli tartományvezérlőn
- Servicepack2 hopsza, felugrik.
- Megvárjuk, amíg a replikáció szétterjed.
- ADSIEdit-tel ellenőrzés az összes DC-n. (Exchange server objektum, version tulajdonság. Hogy melyik szám mit jelent, itt találod.)
- Jöhet a visszaállítás. Binárisok visszatöltése az Exchange szerveren. Fontos, hogy a szolgáltatások még mindig állnak, tehát az adatbázis könyvtár még érintetlen.
- Tartományvezérlő újraindít, Directory Service Restore üzemmódban.
- Ideges kapkodás, hogy hová is írtuk fel évekkel ezelőtt a DC lokáladmin jelszavát.
- System state mentés visszatöltése.
- A konfigurációs névtér autoritatívvá jelölése:
– ntdsutil elindít, megkapjuk a promptot,
– beírjuk, hogy ‘authoritative restore’,
– majd azt, hogy ‘restore subtree „CN=Microsoft Exchange,CN=Services,CN=Configuration,DC=cegnev,DC=hu”‘
– felírjuk, hogy hová gyártott az ntdsutil az ldf segédfájlokat,
– quit.
Ide elkél némi magyarázat, legalábbis a segédfájlokkal kapcsolatban. Egyszer már írtam az ún. Linked Value tulajdonságtípusról – itt is erről van szó. Egész egyszerűen van néhány olyan tulajdonság(backlink) a konfigurációs névtérben, melyek értékei más – esetlegesen más névtérben lévő – objektumtulajdonságok értékeiből állnak össze. Ezeket az értékeket az ntdsutil roppant intelligensen kiteszi egy ldif fájlba. - Újraindítjuk a tartományvezérlőt, normál üzemmódban.
- Elindítunk egy replikációs hullámot: repadmin /syncall dc.cegnev.hu /e /d /A /P /q. (Ez ugyan lereplikál mindent, de csak a konfigurációs névtér lett autoritatív, a séma ugye intakt, a domain névtér meg normálisan replikálódik.)
- Végül visszatöltjük a backlink értékeket: ldifde -i -k -f fájlnév.ldf
- Szépen megvárjuk, amíg a replikáció elvégzi a dolgát. Leellenőrizzük mindegyik tartományvezérlőn, hogy a verziószám visszaállt Sp1-re.
- Biztonság kedvéért Exchange server újraindul, teszt levelezés, pihentetés.
- Végül Sp2 telepítés, megeszi-e. Megette.
Nos, ennyi. Ez már megnyugtatónak tűnt, nekikezdhettünk.
Természetesen végül nem volt semmilyen probléma.
ps: A fenti recept Windows Server 2003 Sp1 operációs rendszerű tartományvezérlők esetén működik! AD2000 esetén jócskán más a metódus.
Exchange esettanulmány
Van egy ügyfelünk és van nála egy régóta elhúzódó probléma.
Az Exchange organizácójuk nem túl bonyolult, a lentebbi módon néz ki.
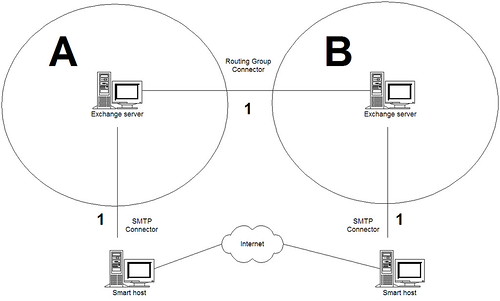
Azaz két administrative/routing group, jelezve, hogy ez valamikor két cég volt, külön IT szervezettel. Mindkét RG-nek saját Internet kijárata van. Mindkét smarthoston X-re végződő operációs rendszer fut. Ami még fontos a történet szempontjából, hogy ‘A’ cég rendszergazdája valamivel paranoiásabb, mint ‘B’ cégé… azaz a smarthoston nem engedi át azokat a kifelé menő leveleket, melyeknek feladója @a.ceg.hu. ‘B’ rendszergazda ellenben mindenkit kienged.
Az elvárt működés az lenne, hogy mindenki a saját kijáratát használja. Ezzel szemben, amennyiben felvesszük ‘A’ cég SMTP konnektorába a * névteret, minden levél – tehát a ‘B’-ben feladottak is – ‘A’ kijáratán mennek ki. Ahol a smarthost el is meszeli a nem oda valókat. Emiatt most gyakorlatilag ‘A’ konnektor le van zárva, mindenki ‘B’-n keresztül levelez.
A cégnél az email meglehetősen kritikus, tehát idő sem nagyon van kísérletezni, meg hibázni sem nagyon lehet.
Kollégám egy évvel ezelőtt kapott egy éjszakát, reggelig sportolt a rendszeren, de nem jutott előbbre. Amint hozzányúlt, felvette a * névteret, megindultak vissza ‘A’ smarthostjáról az NDR-ek, lett is egyből sírás-rívás, árvák könnyeinek potyogása.
Én múlt héten kezdtem el foglalkozni az esettel, péntek délután volt lehetőségem megpiszkálni a rendszert.
Első körben – még hétközben – felvettem mindkét konnektorra egy senki más által nem használt névteret, ahol nekem van egy eldugott postafiókom. (Nem írkálom ki egyenként, de minden smtp névtérhez 1-es súly tartozik.) Ez délután volt, szépen hagytam, hagy terjedjen el az infó a Link State Táblában (LST). Másnap reggel teszteltem, mindkét szerverről küldtem egy levelet magamnak, gyönyörűen a megfelelő kijáraton ment ki mindegyik. Nem lesz itt semmi probléma – nyugodtam meg – akár munkaidőben is át lehetne állítani.
Azért csak megvártam a péntek délutánt. Beírtam a * névteret ‘A’ konnektorába, újraindítottam a Routing Engine Service-t (RES) és az SMTP szolgáltatást, megvártam, amíg az LST frissül, mindenhonnan küldtem egy tesztlevelet – és csak az ‘A’-ból feladott érkezett meg. Jeges rémület szorította össze a szívemet, gondolatban elnézést kértem a kollégámtól, hogy ennyire amatőrnek néztem – és megpróbáltam összekapni magam, hogy megbírkózzak az ismeretlennel. Első körben gyorsan visszaállítottam a kiindulási állapotot, nehogy elvesszenek a levelek. Mondhatnád, hogy mit vacakolok, az smtp konnektoron be lehet állítani, hogy milyen csoportok küldhetnek levelet rajta keresztül, egyszerűen fel kell venni, hogy ‘A’ konnektoron ‘B’ userek ne küldhessenek – és már kész is, lehet menni a pénztárhoz felmarkolni a zsét. Ugyanerre vezetne, ha mindkét konnektoron csak a saját RG-jére érvényesen definiálnám a névtereket. El is raktároztam ezeket a megoldásokat, végső esetben jók lesznek – de itt elsősorban a ‘miért’-et kell megtalálnom és tisztességes megoldást összerakni. A workaround-dal mindig az a baj, hogy nem ismerjük, mi váltja ki, nem tudjuk, milyen más rendellenéséget okozhat. Nehéz így felelősen rendszert üzemeltetni.
Szóval jöhetett a kísérletezgetés. Első körben lecsekkoltam minden elemet. (Az organizáció messze nem ilyen egyszerű, mint amit rajzoltam. Az csak a lényegi vázlat.) Aztán elkezdtem rugdosni a rendszert. (Igen, így identifikálunk: belerúgunk a rendszerbe és lessük, mekkorát sikít.) Nos, láttam olyan csodákat, hogy szemem-szám elállt. A legdurvább az volt, hogy felvettem jó magasra (10) az RG konnektoron a súlyokat, RES újraindít, tesztlevél. És igen, megjött mindkét feladótól! Boldogan csaptam a levegőbe, majd a biztonság kedvéért megnéztem mindkét levél fejlécét. Elég sokáig néztem, egyre üvegesebb szemekkel… majd szóltam Janinak, hogy jöjjön ide, mert ilyesmit még ő sem látott. A ‘B’ szerveren lévő postafiókból a levél az 1-es súlyú út helyett átment a 10-es súlyú RGC-n, majd az ottani 1-es súlyú SMTP konnektor helyett visszament B szerverre – újabb 10-es súly -, végül most már kiment a ‘B’ SMTP konnektoron; azaz mindösszesen összeszedett 21 egységnyi súlyt, az 1 egység helyett. A sportember.
Ha azt mondom, hogy tanácstalan voltam, akkor meglehetősen enyhén fejeztem ki magam. Először is elmentem darts-ot dobálni pár percig. Ránézésre nyugodtnak látszódtam, a figyelmes szemlélőnek legfeljebb az tűnhetett fel, hogy a tábla mellé dobott nyilak is beleálltak a falba. Pedig műanyag hegyűek.
Végül érdekes módját választottam a monitorozásnak. Beírtam újból a * névteret ‘A’ konnektorába, újraindítottam a szolgáltatásokat, mindeközben egy perces auto frissítésre állítottam a Winroute-ot – és fel-alá szkrolloztam a képernyőn, hátha elkapok valahol valami érdekeset. És úgy döntöttem, hogy nem leszek gyáva nyúl, teszek rá, hogy NDR-ek jönnek vissza.
Nos, igen, végül csak elkaptam valamit.
A következő sorozatot láttam:
- Körülbelül két perc telt el, amíg ‘A’ SMTP konnektora state up állapotba jutott.
- Körülbelül öt perc telt el, mire az LST frissült.
- Majdnem tíz percbe telt, mire ‘B’ SMTP konnektora state up állapotba került.
Itt van minden. A magyarázat is, és a megoldás is.
Látható, hogy van egy olyan kritikus öt perc, amikor az organizáció már észleli, hogy két konnektoron is rajta van a * névtér, de a ‘B’ konnektor még nem él. Tehát ebben az öt percben az ‘A’ felé küldi a leveleket. Egyéni balszerencse, hogy mind a kollégám, mind én ebben az öt percben teszteltünk, majd a sikertelen teszt után pánikszerűen álltunk vissza az eredeti állapotra.
Nézzük meg az egyes eseteket:
- Amikor a teszt névteret vettem fel, nem siettem. Délután beírtam, elmentem haza, reggelig volt ideje elterjedni a változásnak. Azaz nem indítottam újra a szolgáltatásokat, nem került egyik konnektor sem state down állapotba. Persze, hogy ment minden rendben.
- Na, azzal a súlyemelővel még a hiba gyökerének ismeretében sem igen tudok mit kezdeni. Valószínűleg pont úgy küldtem meg a tesztlevelet, hogy ‘B’ kijárata még éppen nem élt, ezért átment ‘A’-ra, aztán ott valahogy észrevette, hogy időközben életre kelt a ‘B’ SMTP konnektor – és visszament afelé. Elég perverz – és nem is igazán értem, mert nem logikus.
Gyors teszt, immáron jócskán kivárva – és minden levél a saját kijáratán ment ki.
A feladat megoldva.
Aki velem együtt dőlt hátra a székében, elégedetten csettintve, hogy ez egy korrekt lezárása volt az esetnek – igen nagyot tévedett. Ez a megoldás ugyanis – dacára annak, hogy működik – életveszélyes.
Gondolkodjunk el a következő eseteken:
- ‘B’ rendszergazda újraindítja az Exchange szerverét.
- Vagy elég csak a Routing Engine Service-t újraindítania.
- Ledől a ‘B’ smarthost. Oké, tudom, hogy Unix, de a kalapács ellen azok sem rendelkeznek erős védelemmel.
Mindegyik esetben hosszabb-rövidebb ideig az organizáció azt fogja látni, hogy csak ‘A’ konnektor él – és mivel nem tud róla, hogy azon az úton leselkedik Szkülla és Karübdisz – így arra küldi az összes levelet. Azaz nem az történik, hogy ‘B’ konnektor felállásáig a levelek egy kényelmes queue-ban várakoznának – nem, ehelyett egy gusztustalan NDR-rel pattannak vissza.
Szépen végiggondolva a szituációt, visszaállítottam az eredeti állapotot, leírtam, mit tapasztaltam – majd az egészet bedobtam az ‘It needs business decision’ dossziéba.
Amíg ‘A’ rendszergazda nem enged ki minden levelet, addig jobb, ha az a konnektor nem is működik.
A misztikus public folder replikáció III.

Az előző részekben szó esett a public folderek felépítéséről, részletesen leírtam egy egyszerű replikációs folyamatot és alaposan belementem abba, hogy milyen mechanizmusok támogatják az atombiztos multimaster replikációt.
Jelen írásban viszont inkább arra térnék ki, mi van akkor, ha valami mégsem működik annyira biztosan? A gyors válasz könnyű: akkor a replikáció betonbiztosan nem működik.
A legegyszerűbb megoldás, ha néhány konkrét eseten keresztül mutatom be ezt a nemműködést.
IV Tipikus problémák és megoldások
A címben első ránézésre van egy kis barokkos túlzás. A tipikus probléma ugyanis úgy néz ki, hogy nem működik a public folder replikáció. És itt meg is szokott állni a tudomány. Nem is csoda – a folyamat mélyebb ismerete nélkül az adminisztrátor leginkább csak hadonászik fakardjával a sötétben.
Nézzük, milyen eszközökre lesz szükségünk a megoldási folyamatban:
- Eventlog, applikációs log.
- Message tracking center.
- ADSIedit.
- ArchiveSink.
- Józan ész.
Különösen az utóbbi fontosságát nem győzöm hangsúlyozni. A többi simán megvásárolható a boltban – de a tiszta gondolkodás nem található egyik polcon sem. Nevelgetni kell.
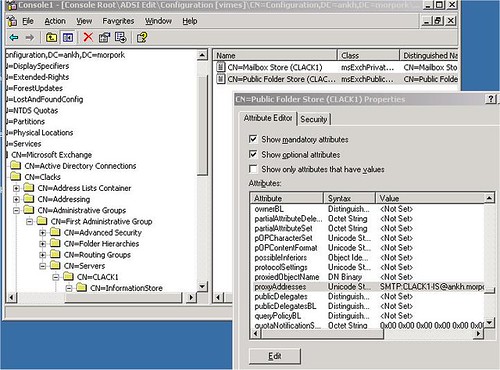
Az első, józan észhez kötődő megjegyzés: mindig pontosan legyünk tisztában vele, hogy hol vagyunk. Multimaster replikációnál talán ez a legfontosabb kiindulási pont. Tudni kell, melyik szerveren változtatunk és mely szervereken várjuk, hogy a változás – a replikáció révén – megjelenjen. Az Exchange System Manager-ben állítható, hogy melyik Exchange szerveren lévő public foldert támadjuk be. (Connect to… opció)
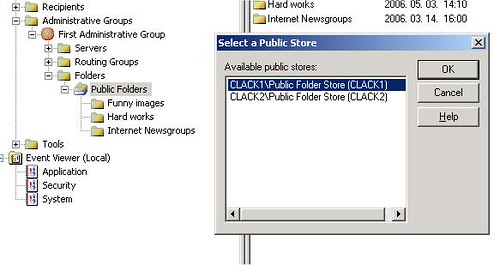
5. ábra A vizsgálandó Exchange szerver kiválasztása
Ha kliens oldalról piszkálódunk, akkor kiindulhatunk abból, hogy első körben azt a replikát fogjuk elérni, mely azon a szerveren van, ahol a postafiókunk. Amennyiben azon a szerveren pont nincs replika, akkor valószínűleg azt a szervert fogjuk elérni, amelyiken van replika és egy site-on van a postafiókunkat tartalmazó szerverrel. Habár létezik tool ennek pontos kiderítésére (MFCMAPI), de a használata nem nevezhető egyszerűnek. (Ez a segédeszköz az Information Store-ban tárolt paramétereit mutatja meg az egyes foldereknek. Jelen esetben a PR_REPLICA_SERVER paraméter tartalma érdekelhet minket.)
Ejtsünk még pár szót az applikációs logról. Alaphelyzetben az Exchange szerver nem túl bőbeszédű. Ha azt szeretnénk, hogy megeredjen a nyelve, fel kell emelni a logolás szintjét. Ezt megtehetjük a grafikus felületen vagy a registry-n keresztül. Nyilván van valami különbség a kettő között: a grafikus felületen beállítható maximum paraméter 5-ös erősséget takar, míg a registry-n keresztül beállíthatjuk az abszolút legerősebb logolási szintet, a 7-est.
Még azt kell eldöntenünk, melyik paraméteren állítsunk erősséget. Habár a Replication Errors paraméter nagyon illegeti magát, gyakorlati haszna nincs. Válasszuk helyette a Replication Incoming és a Replication Outgoing paramétereket; becsületszóra jobban járunk velük.
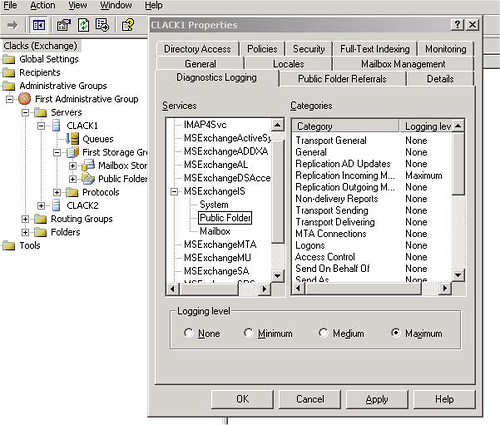
6. ábra Logolási erősség állítása grafikus felületről
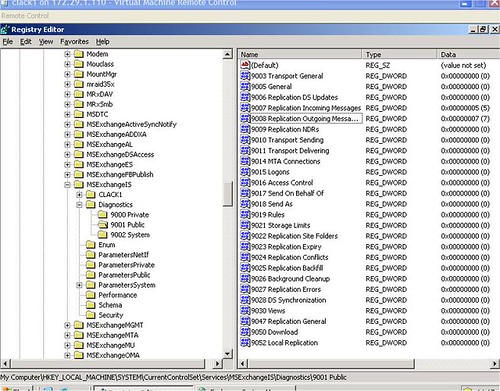
7. ábra Logolási erősség állítása a registry-ben
Érdemes megfigyelni, hogy a 6. ábrán bekattintott Maximum erősség a 7. ábra szerint egyáltalán nem a maximum.
És most akkor jöjjenek a tipikus problémák.
1 A szerver nem publikálja a változásokat
Szokásos alaphelyzet. Jön Béla és módosít egy nyilvános mappa elemet – mert Béla már csak ilyen. Csakhogy Jenőnél a változás nem jelenik meg.
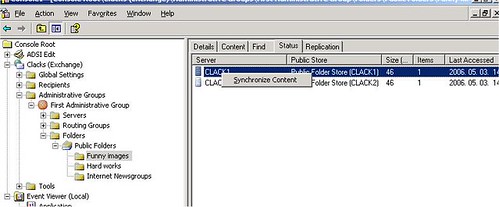
Induljunk el a változás forrásától. Első körben nézzük meg, azon a szerveren, amelyen a módosítás történt, be van-e kapcsolva a public folder replikáció. (A replikáció időzítését a 4. ábrán látható panelen tudjuk megnézni.) Az ‘always run’ érték jelenti a 15 percet. A legtöbbször egyébként nem folder szinten szokták hangolni a replikációs időzítéseket, hanem store szinten.
Amennyiben be van kapcsolva, akkor emeljük fel az események logolási szintjét a korábban említett módon és változtassunk meg egy újabb elemet. Most jön 15 perc dartsozás. (Alternatívaként lehet a képernyőt is bámulni üveges szemmel.) Ha nem találunk az applikációs logban 0×4 vagy hierarchia változtatás esetén 0×2 bejegyzést, akkor gáz van – a szerver nem publikálja, hogy rajta változtatás történt. Nagy valószínűséggel a PFRA nem indult el – és ez bizony nagyon nem jó hír. Általában ez az eset mixed módú organizációkban fordul elő, ahol még vannak 5.5 szerverek is. (Egy ilyen esettel foglalkozik pl. a 272999 KB cikk.) Ugyanezt a jelenséget tapasztaljuk, ha az 5.5 – 2000/2003 rendszerek között nem működik megfelelően a legacyDN – SID konverzió. (Ilyen eset lehetséges, ha a konverzió során ugyanaz a SID generálódott le két különböző felhasználónak. Értelemszerűen, ezt manuálisan kell korrigálni.)
2 Tényleg a szükséges szervernek lett elküldve a replikációs csomag?
Folytassuk az előző esetet. Tegyük fel, hogy 15 percen belül megtaláltuk a 0×2/0×4 bejegyzést az applikációs logban – tehát a szerver elküldte a replikációs csomagot. Kérdés, hogy hová? Ugye az alap probléma, hogy Jenő szerverén nem látszik a változás – azaz a szerver nem kapja meg a csomagot. Ez klasszikus levéltovábbítási probléma – úgy is kell megoldani.
Ilyenkor vesszük elő a Message Tracking Centert. Jó tudni, hogy a replikációs üzeneteket a PFRA-k úgy küldözgetik egymásnak, hogy mind a feladó, mind a címzett az adott szerver Public Folder Store szolgáltatása. Ezek smtp címei pedig a következőképpen generálódnak: <servername>-IS@<domain.name>; azaz pl. Clack1-IS@cegnev.hu.
Mind a hiba oka, mind a konkrét megoldás sokféle lehet. Mindet nem áll szándékomban sorba venni, inkább leírok egy konkrét esetet a saját élményeimből. Clack1-n változtattunk public folder tartalmat, de a változás nem ment át Clack2-re. Applikációs log szerint a replikációs üzenet elment – és ugyanezt tapasztaltam a Message Tracking szerint is. Clack2 ennek ellenére már nem kapta meg a replikációs csomagot. Hirtelen ötlettől vezérelve elkezdtem másképp kérdezgetni a Message Tracking-et. Addig ugyanis úgy vizsgálódtam, hogy beírtam egy időintervallumot és ott látszott, hogy igen, az egyik IS elküldte a másiknak a levelet. Most beírtam a konkrét emailcímeket (lásd fent), és amikor a címzettére kerestem rá, akkor nem kaptam találatot.
Kis kitérő: az smtp cím érdekes állatfajta. A címzett címe szerepel egyfelől a borítékon, másfelől magában a levélben is. Az ‘okos’ levélmutogatók ezt a belső címet szokták mutatni, mondván, hogy ez való inkább emberi fogyasztásra. Sajnálatos módon a levéltovábbítás a borítékra írt cím alapján működik – legalábbis az első lépésben. (A reply… az egy más világ.)
Nos, ez történt itt is. A szép cím a levélben tényleg a távoli IS neve volt, de a borítékra nem került fel semmilyen cím sem – tehát a levelek elmentek a nagy fekete semmibe. Ez onnan derült ki, hogy elővettem az ADSIedit segédprogramot és megnéztem az Active Directory konfigurációs névterében, hogy a célzott szerver IS szolgáltatásán belül konkrétan mi a Public Folder Store smtp címe. Konkrétan üres volt.
8. ábra Public Folder Store smtp címének tárolási helye a címtárban
Miután beírtam a megfelelő címet és megvártam, hogy szétreplikálódjon, beindult a public folder replikáció is.
3 Eljutott-e odáig a csomag?
Ha Clack1 elküldte a replikációs csomagot és ténylegesen Clack2 smtp címét írta bele, de ennek ellenére Clack2 mégsem kapta meg azt (nem szerepel az applikációs logjában a 0×2/0×4 üzenet), akkor ott levéltovábbítási problémával állunk szemben. Belépett a levélelkapó manó az organizációba. Ilyenkor segíthet a Message Tracking, az ArchiveSink segédprogram, illetve az egyes konnektorok és egyáltalán az email routolás átnézése. (Ez utóbbiról már írtam egyszer egy részletesebb cikket.)
4 A fogadó szerver megkapja a replikációs csomagot, de nem történik semmi.
Egyre cifrább, mi? Clack2 megkapta a replikációs csomagot – a Message Tracking szerint – de az applikációs logja nem mutat semmit. (Nyilván itt is maximálisra állítottuk a két paraméter logolási szintjét.) Ilyenkor mi van?
Alapvetően két eset lehetséges.
Elképzelhető, hogy a szerveren korrupttá vált a Replication State táblázat.
Gyors ismétlés: ez egy olyan táblázat, melyben a szerver adminisztrálja az egyes replikációs csomagokat. Minden replikabeli foldernek külön sora van.
Simán előfordulhat, hogy egy sor kiesik a táblázatból. Ekkor, hiába szerepel Clack1 replika listájában, hogy Clack2-n is van a konkrét foldernek replikája, és hiába látszik ugyanez Clack2-n is a grafikus felületen, Clack2 a Replication State tábla alapján úgy érzi, hogy nála bizony nincs – és lepergeti magáról a replikációs csomagokat. Gyógyítani lehet a klasszikus kiszáll-beszáll módszerrel: eltávolítjuk a folder replika listájáról Clack2-t, majd újra visszarakjuk.
Azért létezik ennél cizelláltabb megoldás is, az isinteg programnak van egy olyan kapcsolója, hogy replstate. (Egész konkrétan lásd a 889331 KB cikkben.)
Nézzük a másik esetet.
Exchange2003 esetében képbe kerülhet egy jogosultsági problémára visszavezethető hibaforrás is. Az Exchange2003 ugyanis igényli, hogy a feladó szervernek meglegyen a Send As joga a fogadó szerver virtuális SMTP szerverén. Ellenkező esetben a fogadó szerver nem fogja tudni lejátszani a replikációs csomagot. Alaphelyzetben ez a jogosultság adott… de a jogosultságok arról híresek, hogy az adminisztrátorok elállítgatják. (Nem feltétlenül kell persze semmit sem elállítani: elég, ha a feladó szerver kikerül az Exchange Domain Servers csoportból.) Hogy cifrázzam a helyzetet, olyasmi is előfordulhat, hogy habár a jogosultságok léteznek, de a fogadó szerver Kerberos hiba miatt képtelen autentikáltatni a feladó szervert.
5 Tudja-e a PFRA, hogy hiányzik adata?
Honnan is tudná az a szerver? Emlékszünk rá, egy konkrét folder teljes CNset-je a státusz üzenetekben utazik. Ha kimarad egy változás, akkor bizony a szerver egész addig nem értesül a változtatásról, amíg ugyanabban a folderben nem következik be egy másik változás. (Eltekintve azon ritka esetektől, amikor módosítjuk a replika listát vagy visszatöltünk mentésből egy régebbi állapotot – illetve el nem telik 24 óra a legutóbbi változás óta.)
Arra is emlékszünk, hogy a hiányzó változás rákerül a szerver kívánságlistájára, majd a timeout letelése után a szerver elküldi a backfill igényt. (0×8) A kívánságlistát közvetlenül nem tudjuk olvasni, de ha meredt szemmel figyeljük az applikációs logot, akkor észrevehetjük a 0×8 üzeneteket. Ha van ilyenünk, akkor biztosak lehetünk benne, hogy a PFRA tudja, hogy valami hiányzik.
A módszer egyetlen hátránya, hogy kicsit sokat kell várni. Ha például egy másik site-on van egyedül megfelelő replika, akkor az első timeout 12 óra, a második 24 és a harmadik 48 óra. Ennyi még dartsból is sok.
Le lehet egyszerűsíteni a szituációt úgy, hogy rákényszerítjük a szervert arra, hogy vegye tudomásul a hiányzó változást. Ehhez természetesen különböző módszerekkel státusz információkkal kell bombáznunk.
-
- A kijelölt szerver 0×20 (status request) csomagot küld a replikáknak.
- A kijelölt szerveren lenullázódik a backfill timeout.
- Egyik lehetőség, hogy elmegyünk egy másik szerverre és megváltoztatunk valamit az illető folderben. Ilyenkor a replikációs csomagba belekerül a folder státusz információja is, tehát a lazsáló szerver biztos megkapja a szükséges információkat.
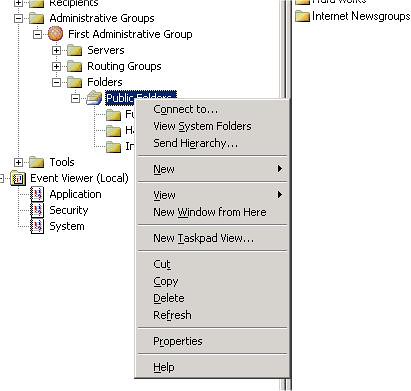
- Van egy remekül eldugott opció, melynek segítségével kikényszeríthetjük a tartalom szinkronizálást.
- Ugyanezt a trükköt tudjuk eljátszani a Send Hierarchy / Send Contents opciókkal is.
- Használhatjuk a korábban említett Replication Flag registry turkálást.
9. ábra Tartalomszinkronizálás kikényszerítése
Ha itt azt mondjuk egy folderen állva, hogy Synchronize Content, akkor két dolog történik:
Ebből az első a lényeges most számunkra: az egyik szerverről kiadott status request ugyanis mellékesen tartalmazza a szerver által ismert státusz információt is – nekünk pedig pont az a célunk, hogy a távoli szerverhez eljussanak ezek az információk.
Konkrétan: ha azt szeretnénk, hogy Clack2 megtudja, hogy nála hiányzik egy változás, akkor Clack1 megfelelő folderén kell megnyomni a Synchronize Content gombot. (És nagy ívben nem fog érdekelni minket, hogy Clack2 visszaküld majd egy 0×10 üzenetet.)
10. ábra Hierarchia replikáció kikényszerítése
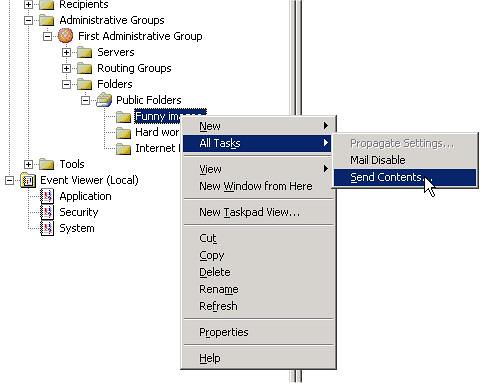
11. ábra Tartalom replikálásának kikényszerítése
Ekkor ugyan backfill válaszokkal küldjük meg a célzott szervert, de jelen esetben ez mindegy; az a lényeg, hogy az státusz információkhoz jusson, azok pedig a backfill válaszokban is benne vannak.
6 Ha tudja, akkor igényli is?
Miután jól kitömtük a szervert státusz információkkal, most már egész biztosan tudnia kell, hogy nem teljesen naprakészek a folderei. Kérdés, hogy ezután fog-e tenni valamit tudásbéli hiányosságainak leküzdésére?
Amit konkrétan szeretnénk látni, az az, hogy a szerver nekiáll a megfelelő replikákat tartalmazó szerverek felé 0×8 (backfill request) csomagokat küldeni. Ugyan várhatunk, hátha egyszer megjelenik az applikációs logban, de azért a timeout értékek meglehetősen ijesztőek. Jobb, ha akcióba lépünk. Az előző pontban szóba került egy módszer, a Synchronize Content. Megemlítettem, hogy ez mellékesen lenullázza a backfill timeout-ot is. Pont ez kell nekünk. Immár azon a szerveren, ahol hiányzik a tartalom, kiadunk egy Synchronize Content parancsot és egyből ki is kell menniük a 0×8 csomagoknak.
Mi van, ha mégsem mennek ki? Pontosabban valamerre kimennek, de pont a minket érintő csomagok nem jelennek meg? (Mi is érdekel minket? Van egy konkrét folder, amelyikben tudjuk, hogy nem frissül egy objektum. Tudjuk, hogy ennek mely szervereken vannak replikái – tehát szeretnénk olyan 0×8 csomagokat látni, melyek e replikák felé mennek és a kérdéses folder tartalmat igénylik.)
Ha ebbe az esetbe ütközünk, akkor jobb, ha tudjuk, hogy kivertük a biztosítékot. Van ugyanis egy ún. lassító mechanizmus a public folder replikációs folyamatban. (Én mondtam, hogy az Exchange fejlesztők nem kapkodó idegbetegek.) Ezt úgy hívják, hogy Outstanding Backfill Limit – és azt szabályozza, hogy a kívánságlista ne nőhessen a végtelenségig. Alaphelyzetben 50 elemet tartalmazhat. Természetesen ha egy backfill csomag beérkezett, akkor a PFRA kihúzza azt a listáról és bekerülhet helyére egy újabb. Viszont ha a szerver olyan csomagokat igényel, melyek már nincsenek meg egyik Exchange szerveren sem, vagy a szükséges Exchange szerver éppen elérhetetlen, akkor ez az ötven kívánság beragad és a többiek nem jutnak lehetőséghez.
Két dolgot tehetünk:
- Nekiállunk dolgozni. Megnézzük az applikációs logban, hogy hová mennek a 0×8 csomagok és mit igényelnek. Aztán megpróbáljuk elérhetővé tennük számukra a szükséges változtatásokat.
- Berugdossuk a dögöt az ágy alá. Registry piszkálással a fenti limit megnövelhető, egészen ötezerig. Ekkor viszont időszakonként komoly backfill viharokra számíthatunk, mely veszélybe sodorhatja az Exchange szerverek elérhetőségét.
7 Foglalkozik-e a többi szerver az igénnyel?
Az eddig leírtak alapján már nagyon könnyen nyomozhatunk. Láttuk, hogy az igénylő szerver elküldte a 0×8 backfill kéréseket.
Vizsgáljuk meg a megcélzott szerverek applikációs logját, hogy megkapták-e a csomagokat?
Ha megkapták, nézzük meg, válaszolnak-e rájuk. Ha igen, akkor azt kell látnunk, hogy megjelennek az applikációs logban a 0×80000002 illetve 0×80000004 backfill válasz üzenetek. (Értelemszerűen nem ugyanannyi válasz lesz, mint amennyi igény érkezett. Az igény azt mondja meg, hogy melyik változás kell neki. A válaszban meg megy a módosított elem – és ha a módosított elem nagyobb, mint a replikációs üzenet maximális engedélyezett mérete, akkor a PFRA több üzenetbe tördeli. Ugyanezért ne essünk kétségbe, ha a válasz nem egyből jelenik meg az igény fogadása után – elképzelhető, hogy sokat kell a csomag összeállításával bajlódnia a PFRA-nak.)
8 Megkapja-e a szerver az igényelt válaszokat?
Szinte már semmit nem kell írnom. A szokásos módon, az applikációs logok és a Message Tracking segítségével nyomon tudjuk követni, hogy mi történt a backfill válasz csomagokkal. Ha a szerver nem kapta meg, akkor levéltovábbítási problémánk van megint. Ha megkapta, de nem érvényesül a változás, akkor pedig a 4. pontban írtakkal állunk ismét szemben.
Nos, ennyi.
Remélhetőleg sikerült utat vágnom a dzsungelben.
Mi van még?
Az irodalom.
A cikk összeállításában sokat segített a Microsoft Technet Exchange szakkönyvtár és az Exchange csapat blogja. Mindkettő erősen ajánlott olvasmány.
A misztikus public folder replikáció II.
Az előző részben szó esett nagy általánosságban a public folderekről, felépítésükről és a public folder replikáció építőelemeiről. Leírtam, alaphelyzetben hogyan replikálódik egy elem, miután módosította őt Béla.
Ebben a részben elindulunk a dzsungel belsejébe. Vigyázat, túristaösvény csak az első pár méteren lesz.
III Kínzó kérdések
1. Mi történik akkor, ha egy szerver – a rajta tárolt adatokhoz képest – régebbi módosítást tartalmazó csomagot kap?
Tulajdonképpen nem is az a kérdés, hogy mi történik – sokkal inkább az, hogy hogyan derül ez ki? Mint korábban írtam, a replikáció nem időbélyeg alapú. A kulcsszereplő jelen esetben a Message State információk közül a predecessor change lista. Ebben van az összes olyan CN, mely valaha is hozzá volt rendelve az adott objektumhoz.
Nézzünk egy példát.
Legyen az objektum predecessor change listája a következő:
| <guid -Clack1>-1210 |
| <guid -Clack2>-6547 |
| <guid -Clack1>-1068 |
Értelemszerűen ez mindegyik replikánál egyforma. Jön Béla és módosítja a Clack1 gépen lévő objektum nevét. Ekkor Clack1 predecessor change listája így fog kinézni:
| <guid -Clack1>-1541 |
| <guid -Clack1>-1210 |
| <guid -Clack2>-6547 |
| <guid -Clack1>-1068 |
Ezt a PFRA belecsomagolja a replikációs csomagba és elküldi Clack2-nek. Ő kicsomagolja és az összehasonlítás után észreveszi, hogy az őnála lévő predecessor lista részhalmaza az újonnan küldött listának, tehát az új lista a király.
Ha valamilyen baleset következtében régebbi módosítást kap meg, akkor azt fogja találni, hogy az új lista részhalmaza a nála lévő listának – kacag egy jóízűt és ignorálja a replikációs csomagot.
2. Mi történik ha egyszerre módosítják ugyanazt a – különböző replikákban létező – objektumot?
Jön Béla és kegyetlenül megint módosítja az előző objektumot. Igenám, de színre lép Jenő is, akit szintén ellenállhatatlan kényszer gyötör, hogy módosítsa ugyanazt az objektumot. Sajnálatosan Jenő postafiókja Clack2-n van. Ráadásul mindez azonos replikációs intervallumon belül történik meg.
Nézzük a példát:
Kiindulási állapot:
| Clack1 | Clack2 |
| <guid -Clack1>-1210 | <guid -Clack1>-1210 |
| <guid -Clack2>-6547 | <guid -Clack2>-6547 |
| <guid -Clack1>-1068 | <guid -Clack1>-1068 |
Béla módosít:
| Clack1 | Clack2 |
| <guid -Clack1>-1541 | |
| <guid -Clack1>-1210 | <guid -Clack1>-1210 |
| <guid -Clack2>-6547 | <guid -Clack2>-6547 |
| <guid -Clack1>-1068 | <guid -Clack1>-1068 |
Jenő módosít:
| Clack1 | Clack2 |
| <guid -Clack2>-7124 | |
| <guid -Clack1>-1210 | <guid -Clack1>-1210 |
| <guid -Clack2>-6547 | <guid -Clack2>-6547 |
| <guid -Clack1>-1068 | <guid -Clack1>-1068 |
Megtörténik a replikációs csomagok elküldése. Ezeket a predecessor change listákat kell összehasonlítaniuk a szervereknek:
| Clack1 | Clack2 |
| <guid -Clack1>-1541 | <guid -Clack2>-7124 |
| <guid -Clack1>-1210 | <guid -Clack1>-1210 |
| <guid -Clack2>-6547 | <guid -Clack2>-6547 |
| <guid -Clack1>-1068 | <guid -Clack1>-1068 |
Látható, hogy egyik sem részhalmaza a másiknak. Replikációs konfliktus keletkezett.
Mi alapján döntik el a PFRA-k, hogy melyik módosítás nyert? Aki azt mondja, hogy majd az időbélyeg dönt, azzal közlöm, hogy ugyan logikusan tetszik gondolkozni, de jelen esetben nincs szivar. A konfliktusnak ugyanis kifejezetten csalafinta feloldását fundálták ki az Exchange fejlesztők.
Maga a PFRA lép akcióba és küld egy ún. conflict message üzenetet Bélának és Jenőnek. Mindemellett a konkrét folder összes tulajdonosánál is bemószerolja őket. Sőt, az üzenetet bemásolja a public folderbe, ahol persze szétreplikálódik az összes szerverre, ahol létezik replikája. Majd ezek után angyali mosollyal kisétál a szobából és hagyja, hogy az érintettek ököljog alapján rendezzék a helyzetet.
(Hierarchia replikációs ütközésnél egy kicsit visszafogottabb a PFRA, ekkor csak a folder tulajdonosait értesíti.)
3 Mi történik, ha el lett lazsálva egy replikáció?
Eddig egy ideális világról beszéltünk. Clack1 észlelte a változást, elküldte a csomagot Clack2-nek, aki lelkesen frissítette is az objektumot. De mi van, ha pont arra jár a levélelkapó manó és a replikációs csomag nem érkezik meg? Ugye, tudjuk, Clack1 a csomag elküldésének pillanatában el is könyvelte, hogy Clack2 is módosított. Ő ugyan több értesítést nem fog küldeni. Clack2 meg elégedetten üldögél a fenekén, fogalma sincs, hogy neki módosítania kellett volna.
Pánikra nincs ok. (Az Exchange egyébként is a türelmes adminisztrátorok platformja.) Létezik egy mechanizmus, mely ezeket a lyukakat hivatott felderíteni. Az egyes szerverek PFRA szolgáltatásai időnként státusz információkkal bombázzák egymást – márpedig a státusz információk CNset-ekből állnak, azok meg CN értékekből. Ebből mindegyik PFRA ki tudja bogarászni, hogy megvan-e nála az összes módosítás, amely egy objektumot érintett. Ha talál olyat, amelyik nála nincs, akkor azt a módosítást felveszi a kívánságlistájára. Ez utóbbit backfill array-nek hívják.
De ne rohanjunk ennyire. Először járjuk körül, milyen esetekben is cserélnek státusz információkat az egyes szerverek?
Mikor kér egy public folder státusz információkat? (0×20, status request)
- Egy folderhez hozzáadunk egy replikát… vagy ellenkezőleg, elveszünk tőle egyet.
- Elindul egy új public folder store.
- Visszatöltöttünk egy store-t backupból és felcsatoltuk.
- Újraindítunk egy store-t, úgy, hogy bekattintjuk az ún Replication Flag értékeket a registry-ben. Ekkor a PFRA kéri az összes hierarchia státusz információkat és a nyilvántartása szerint hiányzó tartalom státusz információkat. (Részletesen lásd a 813629 KB cikkben.)
- Újraindítunk egy store-t, úgy, hogy bekattintjuk az ún Enable Replication Messages On Startup értékeket a registry-ben. Ekkor a PFRA kéri az összes hierarchia státusz információkat és az összes tartalom státusz információkat. (Részletesen lásd a 321082 KB cikkben.)
És vajon mikor küld egy PFRA státusz információkat? (0×10, status message)
- Minő meglepetés: ha valamelyik szervertől status request (0×20) kérést kapott.
- Ha már huszonnégy órája nem érkezett frissítés egy folderhez. Ekkor az összes olyan szerver felé elmegy a státusz üzenet, amelyiken van replikája az adott foldernek.
Végül ne felejtsük el, hogy mindegyik replikációs csomagba bele van csomagolva a frissítésben érintett folder státusz információja.
Oké. Státusz információk jönnek-mennek, Clack2 fejéhez kap: Úristen, hiányzik egy konkrét CN számú frissítés!. Fel is veszi egyből a frissítést a kívánságlistájára. Mivel az Exchange programozók is ismerik azt a dalszöveget, hogy “sokkal jobb, ha úgy szerzed, hogy vágyol utána”, ezért nem elégítik ki egyből Clack2 kívánságát. Várnak. Nem is kispályások, a timeout értékek viszonylag magasak. Ha a megkívánt update olyan Exchange szerveren van, mely azonos site-on van az ígénylő Exchange szerverrel, akkor a timeout értékek sorban: 6/12/24 óra – ellenkező esetben 12/24/48 óra.
Nem mondom, hagytak időt bőven arra, hogy a hiányzó értékek esetleg maguktól is odataláljanak.
Kis kitérő. Háromfajta Exchange adminisztrátor van:
- A legrosszabb típus, a türelmetlen versenyző. Össze-vissza kattogtat és dühöng, hogy miért nem történik semmi. Képtelen felfogni, hogy az Exchange időnként kifejezetten nagy holtidőkkel működő rendszer.
- Egy fokkal jobb, aki üveges szemekkel bámul apatikusan a képernyőre, de legalább nem kattogtat. Neki ugyanis már van esélye arra, hogy eszébe is jut valami értelmes, nagyjából addigra, amikorra a változások is végighullámoznak a rendszeren.
- A legérdekesebb az, hogy külső szemlélő számára az előző adminisztrátor és a profi között nem látszik semmi különbség. A profi is ugyanúgy üveges szemekkel ül a monitor előtt – de közben tudja, mi zajlik a háttérben: tisztában van vele, mire vár.
Vissza a száraz elmélethez. Clack2 tehát tudja, melyik CN számú upgrade hiányzik, felvette a kívánságlistára és letelt az első timeout (6/12 óra). A PFRA fogja magát és küld egy backfill request-et (0×8). Kinek? Ez bizony jó kérdés.
Imhol az algoritmus.
- Clack2 készít egy listát azokról a szerverekről, ahol megtalálható az a replika, mely a kérdéses változáshoz tartozik.
- A lista elemeit sorba rendezi, a következő szempontok szerint:
- Működik-e a szerver?
- Ki a preferred backfill server? (Nem szokott lenni.)
- Mennyi a transzport költsége?
- Milyen verziójú az illető Exchange szerver?
- Hány igényelt változáshoz tartozó csomag található a szerveren?
Nem minden szempont bír azonos súllyal. Általában elmondható, hogy a transzport költsége mindent visz. Logikus, hiszen ha van frissítés az azonos site-on lévő Exchange szervereken, akkor először azoktól kell begyűjteni, még akkor is, ha azok csotrogány 5.5 szerverek.
Most már tulajdonképpen készen is vagyunk. Tudjuk, melyik csomag hiányzik. Tudjuk, melyik szerverről szerezhetjük be optimálisan. Elküldjük neki a backfill request-et (0×8) és meg is kapjuk a csomagot (0×80000002 v. 0×80000004).
Vagy nem. Ha nincs válasz, akkor a szervert úgy veszi a PFRA, hogy nem működik és újra összeállítja a listát. Persze közben a timeout értékek próbálkozásonként szépen nőnek – hasonlóan az Exchange admin ősz szakállához.
4 Mi történik replika hozzáadásakor, elvételekor?
Ez:
- Egy konkrét folderből csak egy példány létezik, Clack2 gépen.
- Clack1-n dolgozva az adminisztrátor hozzáadja Clack1-t a folder replika listájához.
- Clack1 küld egy hierarchia üzenetet Clack2-nek, aki szintén felveszi a replika listára Clack1-t.
- Clack1 küld egy status request-et (0×20) Clack2-nek.
- Clack2 visszaküld egy status üzenetet (0×10) Clack1-nak, benne a folderre vonatkozó státusz információkkal. (Full CNset.)
- Clack1 észreveszi, hogy egyik CN sincs meg nála. Felveszi az egész bagázst a kívánságlistájára.
- Letelik az első backfill timeout. Ha még mindig hiányzik a tartalom, Clack1 elkezdi küldözgetni a backfill igényeket (0×8).
- Clack2 szorgalmasan küldözgeti vissza a backfill válaszokat (0×80000002 v. 0×80000004).
- Clack1 kicsomagolja és lejátssza a módosításokat. Ezzel párhuzamosan törli a megadott számú változást a kívánságlistájáról.
- Amennyiben letelik a következő backfill timeout, Clack1 újra elküldi a backfill igényeket.
- Előbb-utóbb átkerül a kérdéses folder összes tartalma Clack1-re is.
Mint látható, ilyenkor a szerverek státusz információk segítségével derítik ki, hogy az új szerveren olyannyira hiányoznak a változtatások, hogy tulajdonképpen nincs is rajta semmi. Az összes tartalom átlapátolása ilyeténképp a backfill folyamat segítségével történik. Meg lehet saccolni a dinamikát.
Ebből következik egy gyakorlati tanács is. Ha egy konkrét foldert át szeretnénk migrálni egyik szerverről egy másikra, akkor először fel kell venni a folder replika listájára az új szervert, majd megvárni, amíg az új szerveren a Public Folder Instance listában megtalálható lesz a folder. Utána érdemes csak levenni a régi szervert a replika listáról.
5 Mi történik, ha úgy rakok át egy public folder tartalmat egyik szerverről a másikra, hogy a folder replika ablakában hozzáadom a listához az új szervert, leveszem a régit, majd törlöm a régi szerverről a komplett store-t?
Balhé.
Vizsgáljuk meg alaposabban, mi is játszódik le ilyenkor.
Egyáltalán nem meglepő módon, ha letörlök egy szervert a replika listáról, akkor a szerver nem szabadul meg pánikszerűen a tartalomtól. Ehelyett küld egy speciálisan preparált 0×20 status request-et az összes többi replikának. Ennek van böcsületes neve is, Replica Delete Pending Status Request-nek hívják és RDPSR-nek becézik. Ebben a csomagban van egy flag, amely jelzi, hogy a replika függőben lévő törlésben szenved. Ha a többiek megkapják ezt az üzenetet, akkor egy szintén speciális csomaggal válaszolnak. Ez egy különleges 0×10 csomag, melyet Replica Delete Pending Ack-nek hívnak. (A becenév kitalálása házi feladat.) Azt jelzi, hogy a megszűntetni kívánt replika által birtokolt CN változtatások megtalálhatók egy másik replikán is. (Nyilván csak akkor jön ilyen válasz, ha a változás tényleg létezik máshol.) Nna, ekkor törli csak a PFRA a tényleges tartalmat.
Tegyük fel, rossz napunk volt, türelmetlenek vagyunk, mint egy bespeedezett gepárd. Ahogy módosítottuk a replika listát, egyből megyünk is a megfelelő szerver public folderéhez és töröljük a store-t.
Nos, hacsak nem Exchange2003 Sp2 szerverünk van, akkor nagy valószínűséggel ezzel el is veszítettünk valamennyi nyilvános mappa tartalmat. A korábbi verziók ugyanis nem foglalkoznak azzal, hogy üres-e a Public Folder Instances lista a store törlése előtt. (Az Sp2-t is meg lehet erőszakolni, de az legalább figyelmeztet.)
(Van még egy másik különbség is. Az Sp2 előtti szerverek csak egyszer küldik ki az RDPSR-t, aztán várnak, akár az örökkévalóságig az RDPÁ-ra – persze közben a konkrét szerverről nem tűnnek el a folder példányok. Ilyenkor annyit lehetett tenni, hogy újra felvettük a szervert a replikák közé, majd ismét töröltük, ezzel generálva újabb RDPSR-t. Sp2 után gyakorlatilag óránként generálódik újabb RDPSR.)
Mára ennyit. Holnap újra jövök.
A misztikus public folder replikáció I.
Ez a hosszú írás eredetileg nem ide íródott, de aztán később úgy döntött, hogy visszajön Apucihoz. Pusztán a jobb olvashatóság érdekében szedtem darabokra, egyben valószínűleg igen durva lett volna.
Miről is lesz szó? A csapból évek óta folyik az Active Directory replikációjának boncolgatása. Viszont szó sem esik egy másik nagy replikációs témáról, a nyilvános mappák replikációjáról. Az AD replikáció multimaster replikáció, az adatbázis pedig egy JET alapú adatbázis. Ezzel szemben a public folder replikáció multimaster és JET alapú adatbázisok játszanak benne.
Nocsak. Akkor most ugyanarról beszélünk vagy sem?
Természetesen nem. Az egyik esetben az AD ldap adatbázisa replikálódik, a másik esetben az Exchange Information Store adatbázis egyik adatbázisa. Történelmi okokból a két replikáció működési mechanizmusa még csak véletlenül sem hasonlít egymásra.
Hogy még cifrább legyen a helyzet, a public folderek adatai egy kicsit össze is vannak keverve az adatbázisok között. De erről majd később. Most ugorjunk neki az első témának.
I. Általában a public folderekről
Gondolom, itt nincs túl sok szükség szószaporításra. Akinek volt már postafiókja Exchange szerveren – bármilyenen – és próbálta már azt MAPI kliensen keresztül elérni, pontosan tudja, miről beszélek.
Igen, a folder lista alján található nyilvános mappákról. Ezek egyfajta kollektív tárolóhelyek, mindenféle közösen használt anyagokat szoktak itt tárolni az egyes cégek. Láttam már itt céges telefonkönyvet e-mailbe ágyazott Excel tábla formájában, láttam már különböző szintű vállalati rendelettárat… és végtelen a fantázia szárnyalási tere, hogy mi mindent lehet még ide betenni.
Persze mi műszaki emberek vagyunk, minket sokkal jobban érdekel, hogy hogyan is tárolja mindezt az Exchange szerver. Nos, jelen esetben két különböző helyen tárolódnak adatok: egy részük az Active Directoryban helyezkedik el, más részük pedig az Information Store adatbázisaiban. Az első adatcsoporttal most nem szándékozom túl sokat foglalkozni, ezek az adatok jól érzik magukat a címtárban, boldogan használják annak replikációs szolgáltatásait, köszönik szépen. Ide tartoznak az egyes store-ok paraméterei és konkrét nyilvános mappák meglehetősen sok tulajdonsága is. Például amennyiben az egyes folderekhez smtp címet rendelünk, az a cím is a címtárban rögzül.

1. ábra Public folder smtp címe az Active Directory-ban
(Mondjuk egy pillanatra álljunk meg és gondolkodjunk el, hogyan is működik _egymás mellett_ a kétfajta replikáció: a címtáré és az Information Store-ban tárolt nyilvános mappákké. Megvan? Akkor várjunk egy kicsit, amíg elmúlik a szédülés.)
Jelen írás mindemellett azokra az adatokra fókuszál, melyek az Information Store adatbázisában helyezkednek el.
A legfontosabb, hogy tisztában legyünk az adatok tárolási formájával. Pongyolán fogalmazva, a JET tárolási forma lényege, hogy van egy adatbázis, amelyben ömlesztve találhatók mindenféle adatok és egy másik, ehhez kapcsolódó adatbázis, melyben tömérdek pointer mutat rá a másik adatbázis egyes adataira, értelmezhetővé téve azokat. Ezután egyáltalán nem meglepő, hogy a public folderek tárolását is úgy célszerű elképzelni, hogy van külön a folder hierarchia és van külön a tartalom.
Amíg egy szerverünk van, nincs is különösebb baj. Ott vannak rajta a postafiók adatbázisok (melyiken mennyi) és emellett ott van az egy darab MAPI oldalról elérhető public folder adatbázis. (Több, ha megfeszülünk sem lehet.) A hierarchia és a tartalom egy szerveren figyel, az élet szép – és legfőképpen egyszerű. Nagyobb cégeknél viszont teljesen normális, hogy több Exchange szerverük van, esetenként egymástól meglehetősen távoli telephelyeken is. A felhasználói postafiókokkal nincs probléma, azok nyilván azokon a szervereken lesznek, amelyeket a konkrét felhasználók gyors hálózaton keresztül érnek el. De mi legyen a public folderekkel? Valamennyit itt is lehet szeparálni, amennyiben léteznek telephely specifikus folderek… de ez általában csak kis hányad. Marad az, hogy a public foldereket le kell tükrözni mind a központi, mind a telephelyi Exchange szerverekre. (Ez mellékhatásként egyben a rendelkezésre állást is növeli. Egyet fizet, kettőt kap.)
Vizsgáljuk meg, mit is jelent ez a kifejezés, hogy ‘letükrözni’? Le kell tükröznünk a hierarchiát? Nekünk ugyan nem. Az ugyanis olyan, mint az Alien nyála: áteszi magát még a saválló acélmenyezeten is. Amennyiben a folderek jogosultságát nem piszkáljuk, a folderszerkezetet – hierarchiát – minden telephelyen egyformán látni fogják. A tartalom… az már egy másik történet. Itt már mi szabályozhatjuk, hogy mi történjen. Ha akarjuk, letükrözzük. Ekkor ha valaki el akar olvasni egy nyilvános mappában lévő levelet, azt a helyi Exchange szerverről fogja megkapni. Alapértelmezetten biztos lehet benne, hogy ez a levél 15 percen belül friss. Persze nem kötelező tükröznünk. Biztos vannak olyan mappák, melyeket szökőévente használnak egyes telephelyeken. Ilyenkor rábízzuk magunkat az Exchange belső mechanizmusaira: ha nem találja meg a tartalmat azon a szerveren, amelyiken a felhasználó postafiókja van, ki fogja nyomozni, hogy melyik másik szerveren van belőle példány és onnan adja ki. Végül előfordulhat olyan eset, hogy a telephelyen csak szökőévente használnának egy foldert és akkor is tilos nekik: ilyenkor a két Exchange szerver közötti konnektoron egyszerűen le kell tiltani a public folder tartalmak elérhetőségének a közlekedését.
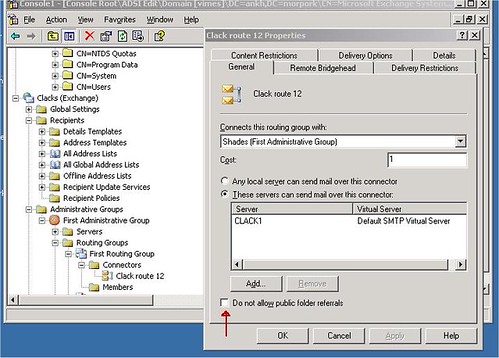
2. ábra Public folder referral tiltása
Közeledünk a cikk fő témájához. Akik üzemeltetnek többszerveres Exchange organizációt, tudják, hogy a tükrözés, vagy nevezzük mostantól népszerűbb nevén – a replikáció – egyáltalán nem olyan kezes bárány, mint ahogy a tankönyvek írják. Sőt. Megismerve a működési mechanizmusát, egyből Pratchett Korongvilágának sárkányai jutottak eszembe: azok a lények annyira bonyolult működésűek voltak, hogy csoda, hogy egyáltalán éltek.
{kind=link}
II. A replikáció közelebbről
Meglehetősen száraz anyag fog következni: bemutatom a replikációban résztvevő szereplőket és a köztük lévő viszonyokat.
Magát a public folder replikációt az Information Store szolgáltatás menedzseli, azon belül is a Public Folder Replication Agent, becenevén PFRA. (Természetesen a replikációs üzenetek szállítását nem ő végzi – azért a mindenkori szállítási mechanizmus felel. Minden másért a PFRÁ-t kell ütni.)
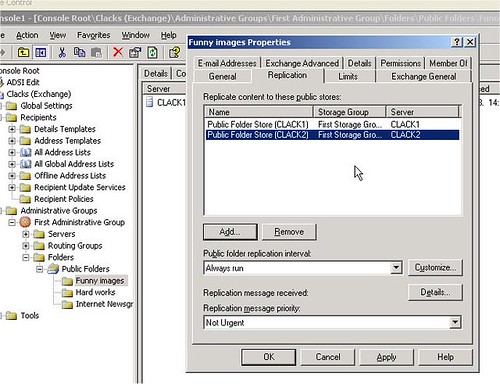
A különböző szervereken található azonos foldereket replikáknak nevezzük.
3. ábra Egy konkrét nyilvános mappa replika listája
Az AD replikáció és a PF replikáció között időnként találhatunk hasonlóságot: az egyik ilyen az, hogy az időbélyeg egyik esetben sem domináns. Az AD replikáció esetében az ún USN érték hordozza a fontos információt, PF replikáció esetén pedig a Change Number, röviden CN.
Ez a következőképpen épül fel: <is -GUID>-counter. Gondolom, nem kell magyaráznom, mindegyik szerver Information Store szolgáltatása objektumként szerepel a címtárban és mint ilyen, van neki egy GUID értéke. A számláló pedig egy szerverhez kötődő, monoton növekvő érték. Amikor bármit változtatnak valamelyik lokálisan tárolt nyilvános mappabéli elemen, akkor a számláló értéke eggyel nő. Az így keletkező CN kötődik hozzá a megváltoztatott objektumhoz és lesz egyben a változás azonosítója is. (Amikor létrejön az objektum, az is egy változás – azaz már születése pillanatában mindenki kap egy CN értéket.)
Ez azért önmagában kevés. Létezik egy olyan fogalom, hogy Message State Information. Minden változáshoz rendelhető egy ilyen csomag. Három fő eleme van:
- CN: change number
- Predecessor change list: Ez egy lista. Azokat a CN értékeket tartalmazza, melyek már korábban kötődtek az illető objektumhoz. Figyelem, itt azok a CN értékek is megtalálhatók, melyek más szervereken keletkeztek!
- Időbélyeg
A Message State Information elemek szerverek között utaznak.
Mindemellett a replikáció adminisztrálásához szükség van lokális információtárolásra is, erre valók az ún. Replication State táblázatok. Durván úgy kell elképzelni, mintha a Message State információkból egy olyan Excel táblát építenénk fel minden szerveren, amelyikben replikánként külön sora van az objektumoknak.
A CN értékeket általában össze szokták kapni egy csokorba. Ezt a csokrot CNset-nek nevezzük. Egy konkrét folder összes objektumának CNset csokrát pedig státusz információnak.
Fontos tisztáznunk, hogy mit tartunk a replikáció elemi egységének. Ez az egység az objektum – azaz ha egy objektum bármelyik tulajdonságának az értéke megváltozik, akkor a teljes objektum utazik. Egész konkrétan:
- Hierarchia esetén pl. létrehozunk egy új könyvtárat vagy megváltoztatjuk egy könyvtár egyik tulajdonságát, – mondjuk a nevét -, akkor a könyvtárobjektum tokkal-vonóval, összes tulajdonságával együtt fog résztvenni a replikációs folyamatban.
- Tartalom esetén új üzenet létrehozása, meglévő üzenet tulajdonságának megváltoztatása egyaránt azt fogja okozni, hogy az üzenet – az összes tulajdonságával együtt – részt fog venni a replikációban. (Értelemszerűen az összes tulajdonságba az elem tartalma is beleértendő.)
Látható, hogy a replikációs mechanizmus igazából sok kisméretű objektum replikációja esetén érzi jól magát. Ha nagyméretű csatolások vannak a levelekben, és valaki bármilyen apróságot is megváltoztat egy levél objektumon, az egész üzenet fog utazni, böszme csatolásával együtt.
A replikációs csomagokat a következőképpen kell elképzelni. A PFRA elkészíti a Message State információs táblát, ehhez hozzácsapja a megváltozott objektumot, a folder státusz információit, az egészet elkódolja, majd rávési a címzett nevét és továbbpasszolja a szállító mechanizmusnak. A kódolás base64 algoritmussal történik és úgy hívják, hogy TNEF (Transport Neutral Encapsulated Format). Az eredmény az oly hőn szeretett winmail.dat csatolás a levélben.
A felsorolás végére hagytam a legfontosabb táblázatot. Akármilyen replikációs lépés is történik, arról bejegyzés kerül az eseménynapló applikációs logjába – feltéve, hogy érzékenyre van állítva a logolás. Az események ‘type’ paramétere utal arra, hogy mi is volt a replikációs lépés.
| Type | Magyarázat |
| 0×2: hierarchia | A hierarchia egyik elemének replikációja történt meg. |
| 0×4: tartalom | A tartalom egyik elemének replikációja történt meg. |
| 0×8: backfill igénylés | Hiányzó elem (hierarchia/tartalom) pótlásának igénye. |
| 0×80000002 (hierarchia) v. 0×80000004 (tartalom): backfill válasz | Hiányzó elemek elküldése. |
| 0×10: státusz | Egy folder teljes CNset-jének elküldése egy replika felé (hierarchia/tartalom) |
| 0×20: státusz igénylés | Egy replikabeli folder teljes CNset-jének megigénylése. |
Ez egy nagyon fontos táblázat. Aki tényleg érteni szeretné a későbbieket, addig ne is olvasson tovább, amíg egy firkálólapra fejből nem tudja reprodukálni ezt a táblát.
Amikor nyomozni kell, hogy mi is történt, ezekkel a számokkal fogunk dolgozni.
Most pedig menjünk végig egy egyszerű replikációs folyamaton, lépésről lépésre.
1. Béla módosít egy elemet a nyilvános mappában. (Ez a változás azon a szerveren fog megtörténni, amelyiken Bélának a személyes postafiókja is van. Amennyiben azon nincs meg a public folder elem, akkor az a szerver fog játszani, amelyikről Béla beolvasta az elemet.)
2. Az illetékes szerveren futó PFRA észleli a változást.
3. A következő replikációs ciklusban (alapértelmezésben 15 perc, egyébként pedig a konkrét public folder store tulajdonságlapján állítható) a PFRA megvizsgálja, hogy létezik-e a megváltoztatott elemnek replikája.
4. A PFRA kioszt egy CN-t és hozzárendeli az objektumhoz.
5. A PFRA elkészíti a replikációs csomagocskát. Ez objektumonként tartalmazza a Message State információs táblát és magát az objektumot. Emellé odacsomagolja még a feladó folder státusz információját is.
A levélforgalom csökkentése miatt egy csomagba nem csak egy változás adatai kerülhetnek bele. Hierarchia változások nagyon jól elvannak egymás mellett, hasonlóan az egy folderhez tartozó tartalomváltozások is. Hierarchia változás nem keveredhet egy csomagon belül tartalomváltozással. Hasonlóan különböző folderekhez tartozó tartalomváltozások sem keverhetők. (Ekkor egy csomagon belül két státusz információ menne.)
6. A PFRA ráírja a csomagra a címzett nevét és feladja. Akárhány replika is létezik, ő csak egy példányban adja fel a csomagot – a többiről már az Exchange szállítási mechanizmusa gondoskodik. A PFRA olyan szinten megbízik ebben a mechanizmusban, hogy minden visszajelzési igény nélkül be is vési a maga kis táblázatába, hogy az illető replikák szinkronban vannak.
Az applikációs logba bekerül egy 0×2 vagy 0×4 típusú bejegyzés, amennyiben érzékenyre van állítva a logolás.
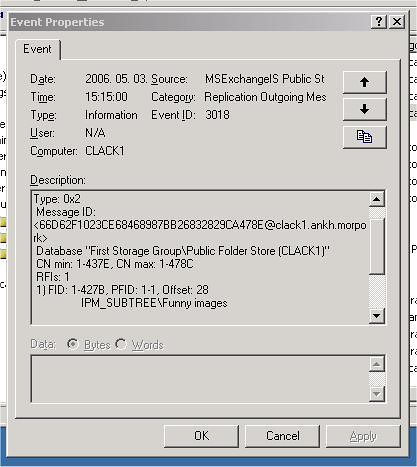
4. ábra Replikációs csomag elküldésére utaló 0×2 bejegyzés az applikációs logban
7. A fogadó szerver PFRA szolgáltatása kicsomagolja a csomagot. Az applikációs logba bekerül egy 0×2 vagy 0×4 típusú bejegyzés.
8. A PFRA elemzi a Message State információs táblák értékét és ez alapján eldönti, mely elemeket kell módosítania a saját lokális adatbázisában.
9. A PFRA elvégzi a módosításokat.
10. A PFRA adminisztrál: átvezeti a módosításokat a saját Replication State táblázatában. A státusz információkban lévő CNset alapján leellenőrzi, hogy a folderre vonatkozóan minden objektumból tényleg a legfrisebb verzióval rendelkezik-e? Amennyiben nem, akkor pánikba esik és a backfill folyamatért szalajt. (Lásd később.)
Ezzel megvolt az alapozás. Holnap folytatom.
Pont, pont, vesszőcske
Egyik ügyfelünk anyacége leszólt, hogy “Béláim, legyetek kedvesek már használni a céges előírás szerinti formát a levelezési címlistában, köszi”.
Kérték, megcsináltuk, hátradőltem. Túlontúl hamar.
Pár nap múlva jöttek a reklamációk: néhány külsős partner nem tud levelet küldeni belsős címekre. Első reflexből visszaírtam, hogy “sorry, de tudomásom szerint az Exchange szerver nagy ívben nem foglalkozik az AD általunk módosított display name paraméterével, itt maximum véletlenek tragikus összejátszásáról lehet szó”. Pedig megtanulhattam volna az eddigi szívásokból, hogy nem jó első reflexből válaszolni, még akkor sem, ha maximálisan biztos vagyok magamban.
A módosítás lényege ugyanis az volt, hogy megvesszőztük a nevet. Azaz ami eddig “Kis Pál” volt, az mostantól “Kis, Pál” lett. Jó, persze fel lehet szisszenni, de hangsúlyozom, ez display name – azaz az a felület, melyet az AD a felhasználónak mutat. A levelezés nyilván a proxyaddresses alapján megy.
És ez bizony így is van. Egészen addig, amíg csak a szerver játszik. Egy igazi admin itt be is hunyja a szemét, mert ami a szervereken túl van, az már a gyehenna. Levelezőkliensek. Fúj.
Nos, boncoljunk levelet.
Egy közönséges email áll egyfelől borítékból és tartalomból. A borítékon van egy feladó (ezt adjuk meg a MAIL FROM smtp paranccsal) és van egy címzett (ezt adjuk meg az RCPT TO smtp paranccsal). A tartalom – mely a DATA smtp parancson belül utazik – meglehetősen összetett valami, pl. meglepő módon neki is van FROM mezője. És itt jönnek be a képbe a levelezőkliensek. A boríték kitöltésével nincs gond, azt kutyakötelességük ugyanúgy kitölteni – de a belső FROM mező már szabad préda. Ma már teljesen elterjedt forma pl. ez: “displayname” <emailaddress>.
Jó, ezt tudjuk. Mi a probléma?
Csináljunk egy kísérletet. Küldjünk magunknak egy levelet, telnettel.
telnet smtp.sajat.domain.hu 25
helo
mail from: nagymagyartarka@sajat.domain.hu
rcpt to: sajat.email@sajat.domain.hu
data
from: “nagymagyar, tarka” <sajat.email@sajat.domain.hu>
subject: apuhodmedbe
pamparampampam
.
quit
És most nézzük meg, mit csináltunk. Küldtünk magunknak egy levelet, melynek a borítékjára feladóként ráírtunk egy fantom címet (nagymagyartarka@sajat.domain.hu), címzettként pedig magunkat (sajat.email@sajat.domain.hu). A trükk ott van, hogy a belső FROM mezőbe beírtuk a saját címünket!
A levelet természetesen meg fogjuk kapni. Nyomjunk rá egy reply-t! Bizony, azt fogjuk látni a címmezőben, hogy nagymagyar, tarka <sajat.email@sajat.domain.hu>, kedvesen aláhúzva. Reménykedőbbek még mondhatják, hogy jó-jó, az Outlook odamaszkol valamit a címsorba, de küldéskor úgyis az email Return-Path mezőjét fogja használni. Ha már itt járunk, nézzük is meg. Nyissuk meg az eredeti levelet, view/options, rögtön az első sorban ott fog vigyorogni, hogy Return-Path: nagymagyartarka@sajat.domain.hu. Tehát, gondoljuk naívan, ha ezt a replyt elküldjük, akkor ez berepül a fekete lyukba – feltéve, hogy valamelyik sunyi kollégánk időközben nem hozott létre nagymagyartarka címet.
Van egy rossz hírem. Az emailt meg fogjuk kapni. A belső FROM értéke űbereli a borítékra írt címet. És ebben a FROM mezőben már szerepel a display név értéke.
Persze még mindig nem látszik, mi itt a baj. Oké, ott van a címben egy vessző. Na és? Kellően körbezártuk idézőjellel, kedves levelezőkliens, tessék nyugodtan nem figyelembe venni.
Most visszaásunk a múltba. Van egy remek oldal, ahol le van írva, milyen karakterek szerepelhetnek az emailcímben. A vesszőre spec azt írja, hogy “megbolondultál?”. Az ugyanis az RFC822 szerint elválasztó karakter. Igenám, de az RFC822-t 2001-ben érdemei elismerése mellett nyugdíjazták, bejött helyette az RFC2822, mely már megengedi a vesszőt, feltéve, hogy idézőjelek között van.
Most már közel vagyunk. Semmi másra nincs szükségünk, mint egy 2001 előtti levelezőkliensre, melynek halvány fogalma sincs az RFC2822-ről. Mit fog csinálni a szerencsétlen, ha ez kerül a címsorába, hogy “Kis, Pál” <kispal@sajat.domain.hu>? Azt fogja mondani, hogy ez két cím: “Kis az egyik, Pál” <kispal@sajat.domain.hu> a másik. Aztán nekiáll visítozni, hogy nem találja a címeket.
Aki szeret kísérletezgetni, nekiugorhat a Freemail webes felületének, remekül hozza a hibát – legalábbis a múlt héten még hozta.
Szuper, megvan a gizda. Mit lehet vele csinálni?
- Szólunk a multi Anyucinak, hogy ne legyen vessző a displaynévben. Oké, oké, tudom, csak a teljesség kedvéért írtam ide.
- Beállítjuk Exchange organizáció szinten, hogy ne küldje el a display nevet, csak az email címet. (Message format ablak, valamelyik fül.) Nekem, kockafejűnek, ez teljesen jó megoldás lett volna, de az üzlet egyből Apage Satanas-t kiáltott.
- Kivezetjük az ősembereket a barlangból a fényre. Magyarul, nekiállunk supportálni az ügyfél üzleti partnereit is, hogyan kell beállítaniuk azt a többezer fajta levelezőklienst, amelyekből néhány nem tudja lekezelni ezt a szituációt.
Az élet szép.
[Update]
Azóta kisérleteztem egy kicsit és rájöttem, hogy nem ilyen egyszerű a helyzet. Könnyű lenne mindent a kliensre tolni, de mégsem ő tehet a balhéról – hanem a levelezőszerver. A kliens átadja a megfelelő smtp parancsot – nagyjából ugyanúgy – de a szerver az, mely – feltéve, hogy nem ismeri, vagy nem jól ismeri a szabványt -, belebukik a vesszőbe.
Tényleg érdekes.
Beláncolva
Régen írtam már szakmai témáról. Ez nektek rossz, nekem jó: ugyanis azt jelenti, hogy mostanában nincsenek nagy szívások a munkahelyemen.
Ez a mostani írás is inkább a munka melletti tanulás eredménye. (Érdekes módszer szerint szoktam tanulni. Előveszek egy könyvet, kinézem, mely fejezetet fogom átnézni, majd nem ritkán amíg a teámat kortyolom és átnézem a reggeli feedeket, postokat, elindulok valamelyik íráson és jó másfél-két órán keresztül próbálom letisztázni, mi is van a cikk mögött. Az előkészített könyv meg csak duzzog az asztalon.)
Van egy olyan valami az Active Directoryban, hogy ‘linked value’. Hallani már hallottam róla, különösen akkor, amikor az AD2003 előnyeit tanultam vizsgára – de olyan nagyon nem mélyedtem bele, mi is ez. Pedig elég érdekes.
Először az a bizonyos előny: az AD2003-ban jobb lett az LVR. Ugye, mennyivel könnyebb immár a lelkünk? De tényleg; az LVR rövidítés a linked value értékek replikációját jelenti.
Most már azért jó lenne tudni, mit is takar az a kifejezés. Könnyű lenne azt mondani, hogy kérem, a linked value az objektum egyik tulajdonságának olyan értéke, mely több elemből áll. Látni fogjuk, hogy ez messze nem igaz, de egyelőre maradjunk ennél a meghatározásnál. Az LVR pedig annyival lett jobb, hogy az AD2003-ban, ha az értékeket tartalmazó tömb egyik eleme megváltozott, nem az egész tömb replikálódik, csak a megváltozott elem. Ez különösen akkor lehet izgalmas, ha mélyebben belemegyünk a susnyásba.
És most akkor felejtsük is el gyorsan az előző defíniciót. Az ugyanis egész pontosan a multi-valued fogalmat fedi, melynek ellentéte a single-valued fogalom. A linked value egy egészen más szempontból történő csoportosítás eredménye. Például ellentéte a DN-valued fogalom.
Nos, eleget ködösítettem már és mivel a blogon nem szótagszám alapján fizetnek, épp ideje rendet raknom. Röviden:
DN-valued: amikor Géza írja be valamilyen eszközzel (kőbalta) a tulajdonság értékét.
Linked value: amikor az AD belső mechanizmusa gyűjti össze az értékeket, más objektumok tulajdonságaiból.
Azaz általában igaz, hogy a linked value körbe tartozó értékek tömbök. De tény, hogy vannak egyelemű tömbök is.
Nézzünk egy konkrét példát:
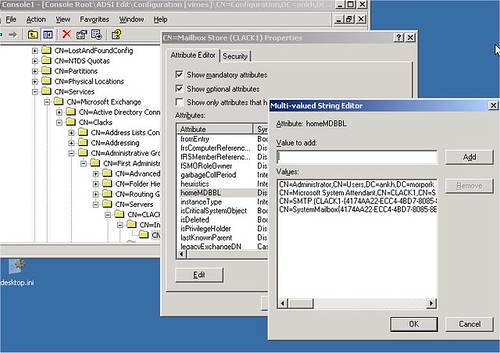
Minden postafióknak van egy homeMDB tulajdonsága. Az értéke lentebb látható. Itt tárolódik, hogy a konkrét postafiók mely szerver mely store-jában virít. Tippeljünk, milyen tulajdonság lehet ez? Akár DN-valued is lehetne… de nem az.
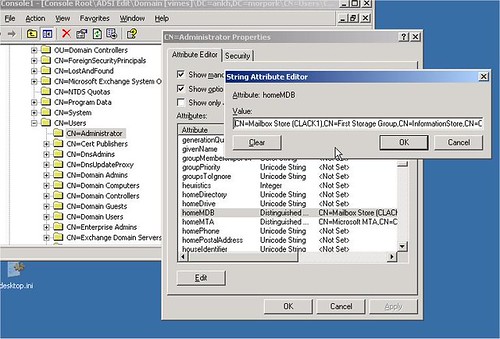
Kényelmi okokból nem az. Ugyanis létezik egy másik tulajdonság, egy másik objektumon. Minden store objektumnak van egy HomeMDBBL tulajdonsága, itt egy tömbben szerepelnek azon felhasználók CN értékei, melyeknek az adott store-ban van a postafiókjuk. Meg se kérdezem, látszik, hogy ez tipikus linked value tipusú tulajdonság. Az AD belső mechanizmusa mazsolázza össze a HomeMDB értékekből a HomeMDBBL (a BL a BackLink rövidítése) tömböt. Az meg csak egyszerű technikai megfontolás, hogy egyszerűbb a mazsolázás, ha a HomeMDB is linked value típusú.
Most gondoljuk el. Van egy Exchange szerverünk, ahol a konkrét store-ban van négyszáz postafiók. Jön az adminisztrátor, felvesz egy újabb felhasználót, postafiókkal. Amíg az LVR úgy működött, hogy mindig ment az egész tömb, ha akár csak egy eleme is megváltozott, addig volt itt nyüzsgés a dróton, rendesen.
De még így is kell trükközni a replikációval. Ilyen trükk, hogy először a DN-valued tulajdonságokat küldik át a replikációs ügynökök a túloldalra (ahol ugye az igazság lakozik) és csak utána jöhetnek a linked value tulajdonságok.
Érdekes dolgok sülhetnek ki ebből.
Vizsgáljuk meg a fenti példát.
Létezik olyan az Exchange-ben, hogy system policy. Ezen belül van olyan, hogy Mailbox Enable User Policy. Ő a felelős a postafiókokhoz tartozó mailnickname, homeMDB, homeMTA és msExchHomeServerName tulajdonságok kezeléséért. Felvettünk egy új felhasználót (igen, leesett az asztalról), az adatai feliratkoztak a replikációra. Most már tudjuk, hogy a homeMDB tulajdonság linked value típusú, tehát egy konkrét replikációs csomag rájátszásakor csak akkor kerül sorra, ha a többi érték már a helyére került. Leterhelt DC esetén ez akár 10-20 másodperc is lehet. Eközben viszont aktivizálódhat a Mailbox Enable User Policiy. Mit lát? A postafióknak már van mailnickname, homeMTA és msExchHomeServerName értéke (mert ezek már megjöttek), de nincs homeMDB értéke. Nosza, ad neki egyet. A helyi szerver default store értékét. Azaz lazán áthelyezte a postafiókot egy másik store-ba. Jó esetben akár még egy másik szerverre is. A legszebb az egészben, hogy mivel ez a módosítás történt később, így ez az érték fog szétreplikálódni a továbbiakban. Aranyos.
Itt található egy KB cikk, amelyikben leírják, hogyan kell módosítani a Mailbox Enable User Policiy szűrőparaméterét, hogy csak akkor induljon be, ha a postafióknak már van homeMDB értéke.
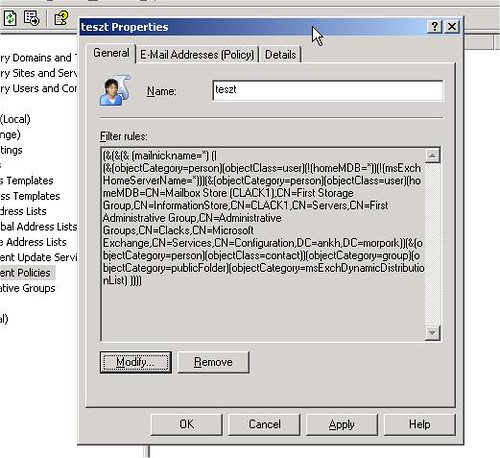
De nem csak ezt a policyt lehet behülyíteni. Gondolkozzunk el, mi történik, ha a recipient policyt például a homeMDB értékhez kötjük? (Ez egyáltalán nem nagy ügy: amikor kiválasztjuk azon postafiókok körét, amelyekre a megadott emailcímnek rá kell esnie, össze lehet kattogtatni olyan szűrőfeltételt, amelyikben szerepel, hogy mely szerver mely store-jára vonatkozzon a policy.)
Itt állítható be a szűrőfeltétel.
És itt látható a konkrét ldap filter – benne gyönyörűen a homeMDB vizsgálat.
Nos, vegyük elő a korábban felvázolt esetet. A replikáció még nem fejeződött be, a postafiók még nem kapta meg a linked value homeMDB értéket. Közben viszont beköszön a recipient policy – melyet ugye a homeMDB-hez kötöttünk. A feltétel nem teljesül, tehát a postafiók a default recipient policyben megadott címeket fogja első körben megkapni. A következő körben, amikor már meglesz a homeMDB értéke, megkapja a jó emailcímeket is, de a korábbi emailcímek nem törlődnek.
Mit lehet itt tenni? Egyszerű: barátaim, ne kössünk recipient policyt linked value értékhez.
Nos, ennyi. A bevezetőben említettem, hogy imádok elcsatangolni egy-egy cikk nyomán. Ez a mostani írás is így született, az ihletője pedig Bill Long szaki kíváló cikke.
Minden összefügg mindennel
De rég is volt, te jó ég. Itt írtam egy orbitális nagy zöldségről. Annyira rég volt, hogy azóta a fiúk ki is irtották azt a KB cikket, felszántották, helyét sóval vetették be.
Ettől persze a problémánk nem múlt el. A komment szerint a hibát bejelentettük a PSS-nek, akik rá is uszították embereiket. Több, mint egy évvel ezelőtt. Nem lehet azt mondani, hogy nem vagyunk kellően makacsok.
A bejelentés után a dolgok mentek a maguk útján. Bekértek mindenféle adatot, beküldtem mindenféle adatot. Aztán eszkalálták a problémát a németekhez, akik megint bekértek mindenféle adatot. Ők is megkapták. Aztán nekiálltak kipróbálni ezt-azt – és az egyik próbára az ügyfél azt mondta, hogy ezt pedig már nem. Itt meg is álltunk. Az MTA szolgáltatás hiánya nem érintette őket annyira tragikusan, hogy belemenjenek egy routing groupok közötti szervermigrációba. Köszönték szépen, inkább nem – még akkor sem, amikor az MS bejelentette, hogy ugye tudják, hogy az MTA nélküli Exchange szerver automatikusan nem támogatottá válik.
Eltelt hét-nyolc hónap. Lehulltak a levelek, fehérre váltott a táj, majd elkezdtek bimbózni a rügyek. Az ügyfélnél leváltották az IT vezetőt, az új fiúval jobban lehetett tárgyalni, belement a migrációba. Létrehoztam egy új routing group-ot, telepítettem egy új szervert, konnektorok, routing rendben. Levelezés tesztelve, frankó. MTA indít – hibaüzenet.
Ez bizony övön aluli volt. Az eddigi koncepció szerint biztosan a szerver telepítésénél történt valami gikszer, amely miatt a routing group nem volt teljesen százas. Nos, nem.
Habár. Az új szerver Windows2003, szemben a régivel, mely Windows2000. És az új szerver azt írja az üzenetben, hogy az MTA elindult ugyan, de aztán rögtön le is állt, mert úgy érezte, őrá itt nincs is igazán szükség. Hasonlóan, mint a perfmon szervíz. Kipróbáltam, tényleg az is ezt írja ki.
Ennyi lenne? Az a nagy rejtélyes hiba pusztán csak annyi, hogy nincs kedve elindulni? (Mely valahol érthető, ugyanis közel-távol sincs Exchange5.5 – mindemellett az organizáció még mixed módú.)
Ebbe akár bele is nyugodhatnék, de az eventlogban könyörtelenül ott van ismét a két ominózus hibaüzenet. Most akkor melyiknek higyjek? A direkt üzenetnek? Az eventlognak? Mit tenne az adott helyzetben Steve Jobs a MOM?
Rábíztam a PSS-re. Ha írásba adják, hogy ez jó, akkor jó lesz nekem is.
Nem mondom, hogy nem inogtak meg. A beküldött adatok szerint olyan pöpec az Active Directory, amilyen csak lehet. Az őscsökevény MTA ráadásul nem is az AD alapján működik, saját adattáblái vannak. Tehát minden észérv azt mondja, hogy tojni rá.
Persze ezt nem adták írásba. Az eltelt időre való tekintettel megint bekértek egy valag adatot. Mire beküldtem, kijött egy újabb EXBPA, így kedvesen megkértek, hogy ismételjem meg az adatgyűjtést. Szóval elvoltunk.
Természetesen próbáltam önállóan is nyomozni, találtam is egy figyelemre méltó levélváltást, de a legacyDN értékek sajnálatosan rendben voltak.
A magam részéről innen már nem igazán bíztam semmiben, de egyszer csak jött egy teljesen vad ötlet a német hapitól. Azt mondta, a hiba oka egy kilométerrel távolabbi Exchange szerveren keresendő. A távolságot nem csak fizikailag kell érteni: bár az Exchange szerverek ugyanabban az organizációban vannak, de AD szinten két különböző szájton, melyek között csak egy harmadik szájton keresztül van kapcsolat, tartományilag pedig nemcsakhogy más domainban üzemelnek, de teljesen más fában is. Azt mondta erre a szerverre az EXBPA, hogy a jogosultsági rendszerében el van vágva az öröklődés. Ezt az üzenetet láttam én is, de csak megvontam a vállam. Igen, el van vágva, valamiért valószínűleg anno el kellett vágni. (Még az se kizárt, hogy pont ennek a case-nek a kezelése során. Legalábbis gyanús, de most nincs kedvem utánakeresni.) Ahogy néztem, elvágáskor rákerült minden jogosultság, tehát pánikra nincsen ok.
Mivel a két szervernek tényleg nagyon halvány köze van egymáshoz, meglehetősen tamáskodtam, amikor ezt az öröklődés elvágást kiáltották ki bűnösnek. De fegyelmezetten beklattyintottam, megvártam, amíg elterjed az AD-ban, mint a kolera, aztán teszt. És itt fehéredtem el: az MTA elindult.
Ez a cikk akkor lenne tökéletes, ha most roppant precíz szikekezeléssel bemutatnám, hogy mi rejlik a megoldás mélyén. De őszintén bevallom, halványlila fogalmam sincs. Annyit sikerült megtudnom, hogy a német srác a regtrace alapján jutott erre a következtetésre – ez viszont megint egy olyan cucc, mely bináris formában gyűjti az adatokat, azaz mezei halandó képtelen értelmezni az outputot.
Ehelyett azt tudom csak mondani Shakespeare kollégával egyetemben, hogy “Több dolgok vannak földön és égen, oh, Horatio, mintsem bölcselmetek álmodni képes”.
És ilyenkor ver ki a víz, ha belegondolok, hogy egy ilyen bonyolult Exchange/AD rendszerbe hány embernek van joga belepiszkálni. És ennyi közül elég, ha csak egy gondolja, hogy nem kell szarozni, csak ide-oda kattintunk néhányat és minden oké lesz.
[Update]
Jó persze, azt észrevettem, hogy miután engedtem az öröklődést, rákerült az ezer éve üzemelő Exchange szerver jogosultságlistájára a nagyon-nagyon távoli tartomány ‘exchange domain servers’ csoportja, read jogosultsággal. De ez valahogy még nem elégítette ki a kíváncsiságomat.
Hülye nevek
Vannak olyanok. Annyira hülye nevek, hogy józan ésszel nem is lehet kitalálni, mi van mögöttük.
Az első példám ahhoz a bizonyos régi szilikáttechnológiai vizsgához kötődik.
Ugyanis megpróbáltam legalább elolvasni az anyagot – de már viszonylag az elején belefutottam egy olyan kifejezésbe, hogy ‘doghouse adagolás’. A porok készülékbe adagolásáról a kézzel – máséval – írott jegyzet több információt nem tartalmazott. Megkerestem pár évfolyamtársamat, de csak annyit tudtam meg, hogy az előadó nem részletezte a dolgot, egyszerűen csak lediktálta.
Én viszont belekapaszkodtam, mint Floki a lábtörlőbe. Próbáltam név alapján kilogikázni. Megkérdeztem idősebbeket, ők sem tudták. Internet, google… ugyan, hol voltak még ezek. Nyomtatott jegyzet? Maximum a holdban. Aztán valószínűleg Buzz Aldrin hozhatott egyet, mert sikerült felkajtatnom egy példányt. Ebből tudtam meg, hogy a roppant tudományosan hangzó szilárdanyag adagolási módszer Jenőt takarja a lapátjával. Komoly.
A másik ilyen kifejezés a ’round robin’ volt. Először tanfolyamon hallottam, még az előző évezredben. Csak néztem nagy gülü szemekkel, de kérdezni nem mertem, mert mindenki más szemmel láthatóan tudta, miről van szó. Vagy csak sokkal értelmesebb képet tudott vágni, mint én. Hiányos angol tudásommal annyit összeraktam, hogy a round az kör, a robin meg vörösbegy… de ebből csak nem állt össze, hogyan lesz ebből redundáns DNS névfeloldás. Azóta persze kupálódtam, megtanultam, hogy az informatikában a ’round robin’ az ‘ad-hoc’ kifejezést takarja, azaz jó magyarosan azt, hogy ‘ahogy esik, úgy puffan’. De hogy ennek mi köze van a ’round robin’ hétköznapi jelentéséhez, mely a ’sokak által aláírt kérdőív’-et jelenti… megint nem tudom.
A harmadik példány még teljesen friss. Exchange 2003 disaster recovery kapcsán olvashatunk olyan módszerről, hogy dial-tone visszaállítás. Első hallásra elsápad tőle még a sokat látott exchange admin is: micsoda… modemen keresztül kell visszaállítani valamit… vagy neadjisten, mobiltelefonról kell sms-ben parancsokat osztogatni? De persze, hogy nem; a névnek megint nincs semmi köze a módszerhez.
Mely nagyjából a következőképpen néz ki.
Legyen egy elszállt Exchange store. Az eredeti mérete – betartva a Microsoft erre vonatkozó ajánlásait – legyen 99.99 GB.
Legyen ez a VIP store.
A CEO legyen teljesen átlagos:
- 1 perc emailtelenség után bevörösödik a feje,
- 2 perc után kitör rajta a légiós betegség,
- 10 perc után sátáni kacagással kezdi kilapátolni a HR ablakán az infomunkások munkakönyveit.
Ezzel szemben a restore rendszer nézzen ki a következőképpen:
- Az adatbázis visszatöltési ideje másfél óra.
- Mire megtaláljuk Jenőt, aki tudja, hol vannak a kazetták, megint másfél óra.
Mit lehet ilyenkor csinálni? Igen, dial-tone.
- Letöröljük az adatbázis maradékait.
- Felmountoljuk az adatbázist. Nem, nem szedtem be semmilyen tudattágító szert… tényleg felmountoljuk a semmit. Az Exchange2003 ilyenkor lesz olyan kedves, hogy létrehoz egy tök üres store-t, azokkal az adatbázis nevekkel, melyek a store tulajdonságlapján szerepelnek.
- Lehet telefonálni a vezérnek, hogy működik a levelezés. Igaz, még nem mindenki éri el a régi leveleit, de a visszatöltés folyamatban van. Lehet levelet írni, kapni. A vezér meg fog nyugodni. Látja, hogy az emberek dolgoznak – és azt a betyár mindenit, tudnak a fiúk, milyen hamar működőképessé tették a rendszert!
- Elindítjuk a visszatöltést a recovery storage group-ba.
- Ha visszajöttek az adatok, ráküldünk egy összefésülést és hipp-hopp, vissza fognak kerülni a régi levelek a postafiókokba. Hátradőlünk és elégedett mosollyal kiélvezzük… azt a pár percet, amíg a munkaviszonyunk még tart. Ugyanis elég hamar rá fognak jönni kedvenc VIP felhasználóink, hogy nem működnek a szabályaik. Naná. Mivel eltűnt az összes. Ugyanis a merge csak a postafiókok tartalmát másolja, a metaadatokat, szabályokat nem. Az üres adatbázis meg egész konkrétan megszámolható szabályt tartalmazott.
- Probléma szál sem, a nyúl már a cilinderben van – csak tudni kell, hogyan húzzuk elő. Miután visszajött az eredeti store a recovery storage group-ba, lemountoljuk. Hasonlóképpen lecsatoljuk a VIP store-t is, majd lemountolt állapotban kicseréljük a kettőt – értelemszerűen mindegyiket a megfelelő névre átnevezve.
- És most már jöhet felcsatolás után a merge – hogy megkapják az ideges fiúk azokat a leveleket is, melyek a visszaállítás ideje alatt keletkeztek.
Jó, mi? De hogy miért dial-tone? A fene tudja.
Részletesebb írás a módszerről Jim McBee blogján.
Eljöttek az angyalok
A címekkel együtt.
Előzmények:
Itt írtam róla, hogy egyik ügyfelünknél váratlan áldás érkezik: közel 33000 kontakt pottyan az égből a címtárukba. Azt is írtam, hogy sikerült megvédeni ezektől a globális címlistát – de nem túl elegáns módon. Mindenképpen szükség lett plusz adminisztrálásra, ami emberi munka, következésképpen hibaforrás. (Nem mintha a gép nem tudna…)
A héten megkaptuk az első adag címet és alaposan szemügyre vettem őket ldp-vel. Ahogy haladtam sorról sorra, egyre szomorúbb lettem. Sajnos bejött a logika – ha ezek az idegen sejtek látszódni akarnak a szervezetünkben, akkor teljesen hasonulniuk kell. Még az exchangeLegacyDN érték is teljesen ugyanaz, mint a saját címeinknél.
Nem hatásvadászatból írom, tényleg így történt: amikor a tulajdonságok végére értem, akkor találtam – az utolsó sorban – egy olyan bejegyzést, amely egyből bearanyozta a napomat. Ez a neve: msExchangeOriginatingForest. A név magáért beszél: annak az erdőnek a neve van benne, ahonnan a címet migrálták. Értelemszerűen azoknál a címeknél, melyek helyben születtek, ez a tulajdonság üres – azaz nem látszik az ldp-ben.
Innentől kezdve egyszerűen csak ki kell egészítenem a GAL lekérdezést a (!(msExchOriginatingForest=*)) feltétellel és az a bizonyos sokat emlegetett Bob már rögtön a bácsikám is.
Címek az égből
Egyik ügyfelünket az a szerencse érte, hogy egyesítenie kellett saját internetes/belső levelezését anyacége belsős levelezésével. Beszélhetnék a két Exchange organizáció egyesítésének szépségeiről, de most elég lesz, ha csak a címekkel foglalkozom.
Nem kis méretekről van szó: az egyesítés révén több, mint harmincezer új cím fog megjelenni a címlistájukban a jelenlegi ezer mellett – miközben az új címeket csak a top50 felhasználó használja.
Megjósolható, hogy itt nagyokat kell majd varázsolni a címlistákkal.
- Kitérő:
Ha valaki úgy képzeli el a címlistát, hogy van egy nagy lajstrom, benne a tagok neve – az hatalmasat téved. Szó sincs ilyesmiről. Az egész lista tulajdonképpen egy bazi nagy LDAP lekérdezés. (Érdemes megnézni az Exchange System Managerben a címlista tulajdonságlapján. Igen, arról a kínai szövegről van szó. Később részletezni is fogom.) Lehet ujjongani: mekkora ötlet, nincs lista, nincs egyenként postafiókba firkálgatás, egyszerűen van időnként egy gyors ldap query és ennek eredményét használják a kliensek. És az ldap query gyors – hiszen ez az értelme az egész adatbázis faszerkezetnek. (Már látom előre, hogy erre a szóra mennyire rá fognak harapni a keresőrobotok.:)
Nos, ha kiujjongtuk magunkat, jöhet a keserves ébredés. Indítsunk el egy ldp-t (support tools) és vizsgáljuk meg egy felhasználó értékkel is bíró tulajdonságait. Fókuszáljunk rá a showInAddressBook tulajdonságra és lassan forduljunk le a székről. Igen. Minden exchange tulajdonságokkal rendelkező objektum tulajdonságai közé be van vésve, hogy mely címlistáknak a tagja.
Láthatod, nem hazudtam. Nevekből álló lista nincs. Van lekérdezés és van objektumba bevésés. Mindezzel sikerült ötvözni a kényelmetlenséget a lassúsággal. Szerencsére a lassú folyamatok időzíthetők, így végülis nem vészes. (De erről megint később.)
No, nézzük a feladatot. A fentről jövő címeket egy OU szerkezetbe fogja beletojni a MIIS, kontaktok formájában. Természetesen a globális címlistában (Global Address List, GAL) meg fognak jelenni, hiszen azért globális a szerencsétlen.
Ötlet1.
Csináljunk egy alternatív globális címlistát. Na jó, értem én, nem kell kötekedni – igen, ez már nem globális. Csináljunk egy listát és valahogy szűrjük ki a beszülető címeket. Mivel az ügyfélnek is vannak kontaktjai, a legegyszerűbb szűrés – kihajítjuk a kontaktokat – kizárható. Vegyük elő megint az ldp-t, nézzük végig az egyes objektumok tulajdonságait, hátha találunk valami jó szűrőfeltételt. Nos, nem. Nincs. Ez nagyon rossz hír. Kénytelenek leszünk csinálni egyet. Erre valók az ún custom attribute tulajdonságok, van is belőlük tizenhat. Most még csak tesztelünk, tehát egy-egy kontakt, csoport illetve felhasználói postafiók második custom attribute tulajdonságába beírjuk, hogy Valami. Innentől már csak csinálni kell egy teszt címlistát, majd összekattogtatjuk a szűrést ezen tulajdonság értékére. Ja, igen, elfelejtettem mondani, az Address List tulajdonságlapján az egyik fül alatt egy kattogtatógép lapul, ezzel lehet összeállítani ldap query-ket. Legalábbis ez volt a szándék. Sajnos a megvalósítás ettől igen messzire került. Röviden fogalmazva botrányos: a fenti feltételt spec nem lehet összeállítani.
Erről van szó: gyűjts le mindenkit, akinél
vagy userpostafiok.customattribute2=’Valami’
vagy kontakt.customattribute2=’Valami’
vagy group.customattribute2=’Valami’.
Nem egy nagy ügy, így nézne ki:
(|
(&(objektum=user)(customattribute2=Valami))
(&(objektum=kontakt)(customattribute2=Valami))
(&(objektum=group)(customattribute2=Valami))
)
A fenti példán remekül el lehet magyarázni az ldap lekérdezés szintaktikáját. Kezdjük az ún. lengyel logikával. Nem azt mondják, hogy ‘3+3=’, hanem azt, hogy ‘+(3)(3)=’. Az & jelenti az ‘és’ műveletet, a | a ‘vagy’ műveletet és a ! a tagadást.
A valóság ennél jóvabb cifrább, nyilván meg kell vizsgálni, hogy egyáltalán léteznek-e a tulajdonságok és az objektum beazonosítása sem ilyen egyszerű.
Kezdjük a kattogtatást.
Első fül: Kellenek a kontaktok, a postafiókok és a csoportok.
Második fül: Kell az összes Exchange szerver.
Marha jól haladunk, már csak egy fül van hátra, ahol a customattribute2 értékét kellene megadnunk.
Harmadik fül: Izé. Csak úgy nem lehet megadni, előtte ki kell választani, hogy user vagy kontakt vagy group. Válasszuk először a felhasználót. Ekkor a tesztnél megjelenik a tesztkontakt és a tesztfelhasználó. A tesztcsoport nem. Oké, válasszuk a csoportot. Ekkor csak a tesztcsoport jelenik meg. Jó, akkor vegyünk fel két feltételt, legyen felhasználó is és csoport is. Ekkor nem jelenik meg semmi. Nyilván az idióta engine ‘és’ feltételt tett közéjük.
Khmm. Valami nem stimmel.
Jelöljük ki a harmadik fülnél csak a felhasználót és nézzük meg, milyen lekérdezést alkot a robot. Imhol.
(&
(&
(&
(&
(mailnickname=*)
(|(&(objectCategory=person)(objectClass=user)(|(homeMDB=*)(msExchHomeServerName=*)))
(&(objectCategory=person)(objectClass=contact))
(objectCategory=group)
)
)
)
(objectCategory=user)(extensionAttribute8=Valami*)
)
)
A valóságban nincs tördelve. Kell hozzá némi áttekintőképesség, szó se róla.
A ‘*’ az az aszteriszk, azaz jelentése: ‘bármi’. A ‘valami=*’ jelentése, hogy létezik-e egyáltalán a tulajdonság.
Tessék jobban átnézni. Where is the loony? A végén. Egyszerűen tök felesleges az (objectCategory=user) feltétel. Ez a hülye kattintógép viszont mindenképpen berakja, csak hol ‘user’, hol ‘group’ paraméterrel.
Ilyenkor vonja meg az ember a vállát. Hülyék vagytok. Majd beírom én a feltételt. Csakhogy a hülyeség ritkán áll meg félúton: a gyönyörű kattogtatógépben nincs custom fül; _nem lehet_ saját keresőfeltételt beadni. Ami már csak azért is meglepő, mert szószerint ugyanígy néz ki az AD custom query kattogtatógépe és ott meg van olyan: egyszerűen a legördülő menüben eggyel több a választható lehetőség és bejön egy üres szövegmező, ahová gépelhetsz.
Elég mélyre ástunk eddig is, itt az idő, hogy még mélyebbre hatoljunk. Nyilván ezek a lekérdezőfeltételek valahol le vannak tárolva az AD-ban is. Vegyük elő kedvenc AD matyizó svájcibicskánkat, az ADSIedit mmc snap-int. (Szintén support tools.) Nagyon remélem, hogy senkinek sem mondok azzal nagy újdonságot, hogy az Exchange organizáció összes konfigurációs beállítása az AD konfigurációs névterében van elrejtve, a Services/Exchange alatt. Nem kell sokáig túrni, hamar meglesznek a címlista objektumok is… és igen, az objektum ‘purportedsearch’ tulajdonsága rejti a keresőfeltételt. Hanyag eleganciával töröljük ki a felesleges kérdést, hajigáljunk pár percig dartsot, majd ha a replikáció megtette a dolgát, nézzük meg immár az ESM-ben a tesztcímlistát. Gyönyörű. Ott van a lekérdezésünk. Írjuk még be a description mezőbe, hogy aki a grafikus felületen módosítani meri a lekérdezést, annak letört kezét fogjuk a seggébe dugni.
Nyertünk.
Eltekintve attól az apróságtól, hogy a teszt címlista nem hajlandó megjelenni kliensoldalon. De ez apróság, összehasonlítva azzal a hátul motoszkáló rossz érzéssel, hogy ez nem frankó. Kurvára nem elegáns. Eleve fel kell tölteni az AD-t ezzel a Valami értékkel. Ha új felhasználót, kontaktot veszünk fel, tudni kell, hogy ezt az értéket is be kell írni, ha látni akarjuk a címlistában. Emberi munka. Hibalehetőség. Tré.
Ötlet2
Ha nemcsak ldp-ből nézzük meg az objektumot, hanem ADSIedit-ből is, egyszercsak szemünkbe tűnik egy canonicalName nevű tulajdonság. Hö. Mifene. Ebben pont az az útvonal van, hogy hol található az objektum. Háde a címek egy meghatározott OU-ba fognak pottyanni – tehát elegendő lenne egy ‘!canonicalName=Domain/OU/*’ feltétellel kiegészíteni a jelenlegi globális címlista lekérdezési feltételét és máris Bob lenne a bácsikánk. Nosza kimásoltam a globális címlista feltételét (még szerencse, hogy engedik használni a ctrl+C-t…), egy editorban hozzáfűztem a fenti feltételt és az egészet bevágtam ADSIedittel a tesztcímlista megfelelő tulajdonságába. Darts, teszt – és üres halmazt kaptam. Habár szeretek dartsozni, de szorított a határidő, így gyorsítottam a tesztelésen. Nem a címlistáknál vacakoltam, hanem a már korábban emlegetett AD custom search ablakban teszteltem a lekérdezést – itt egyből látom az eredményt és van beíróablak. A tesztcímlista lekérdezésével egyből hibaüzenetet dobott. Jó, hagyjuk a GAL-t. Összekattogtattam egy jó általános lekérdezést, az eredményt kimásoltam, editorban hozzátettem a szükséges feltételt és visszamásoltam a custom search mezőbe, és… nem fogadta el! Szószerint ez történt: kurzor be az ablakba, ctrl+v, egy villanás – és nem történt semmi. Nem került be a szöveg. Azannya. Biztos elrontottam valamit az editorban. Fogtam a kattogtatás adta eredményt és egyből visszamásoltam a szövegablakba. Villanás, üres ablak. Mifasz? Adjuk be cseppenként. Editorból kezdtem feltételenként visszamásolni és most már megjelentek a sorok. Szépen haladtam is, de az utolsó feltétel bemásolásakor újból jött a villanás. Bazdmeg. És akkor még messze nem adtam vissza az akkori hangulatomat. Az idióták lekorlátozták a szövegablakban a bevihető karakterek számát. Olyannyira, hogy begépeléssel nem tudom összerakni azt a lekérdezést, melyet kattogtatással igen.
Habár szó sem volt replikációról, de megint sürgős dartsozhatnékom támadt.
Jó, menjünk vissza az elejére. Tesztként beírtam a ‘!canonicalName=Domain/OU/*’ lekérdezést – és erre is hibaüzenet jött. Így már sokkal tisztább a helyzet. Valamiért ez a feltétel nem jó. Miután tíz percig vizsla szemekkel ellenőriztem betűről betűre, hogy nem gépeltem-e el valamit, elkezdtem végre gondolkodni. Hogyan is működik egy AD query? Hol keres?
Hoppá. Ez bizony nem az egész AD-t túrja át, helyette csak az index adatbázist piszkálja – azt az adatbázist, melyet a globális katalógusok kezelnek. Benne van ebben az adatbázisban a canonicalName tulajdonság?
Nézzük meg. Schema management, canonicalName – bizony, üres az összes checkbox. Hát ezért halt meg futás közben az összes lekérdezés.
Itt volt az idő konzultálni az ügyféllel. Előtte azért megkérdeztem a Microsoftot, hogy mekkora plusz terhelést fog okozni az AD-nak egy új tulajdonság felvétele a GC adatbázisba. Ugyanazt a választ kaptam, mint Arthur Dent a bulldózer előtt: “semekkorát”. Ügyfélnek elmagyaráztam a helyzetet, azt mondták, hajrá, felvehetem a tulajdonságot.
Megvártam a péntek délutánt, nekifeszültem a sémának, bekattintottam a ‘vedd fel az index adatbázisba’ checkbox-ot és a ‘replikáld a GC-k között’ checkbox-ot… majd elgyönyörködtem két hibaüzenetben, miszerint ez a tulajdonság a System Class-ba tartozik, tehát se nem indexeltethető se nem replikáltatható.
Csak.
Ötlet3
Más választási lehetőség híján maradtunk az első módszernél. Közben eszembejutott egy újabb komplikáció: kliensoldalon mindenki a globális címlistát használja; ha bevezetek egy új címlistát, akkor mindenkinél át kell állítgatni. Az ügyfél viszont határozottan irtózik a kliensoldali beavatkozásoktól.
Kellene egy újabb ötlet.
Nos, eddig is bátrak voltunk. Miért ne lehetnénk még bátrabbak? Módosítsuk a globális címlistát. A neve marad globális, de kibelezzük és az álca alatt egy nem globális címlista lenne, mely megegyezne azzal a címlistával, melyet most használnak. A tesztlistát meg átberhelnénk és az lenne a tulajdonképpeni globális címlista.
Az ötlet jó. Némi fennakadást okoz, hogy a globális címlista (GAL) nem módosítható. A grafikus felületről. De itt van a jó öreg ADSIedit, és természetesen a GAL-nak is megvan a ‘purportedsearch’ tulajdonsága. A lekérdezés kimásolása a GAL-ból, átmásolása a tesztcímlistába, kibővítése a plusz feltétellel és visszamásolása a GAL-ba alig volt öt perc.
Csak hogy töltsem a helyet, idemásolom:
(& (extensionattribute2=Valami)(mailnickname=*)
(| (&(objectCategory=person)(objectClass=user)(!(homeMDB=*))(!(msExchHomeServerName=*)))
(&(objectCategory=person)(objectClass=user)(|(homeMDB=*)(msExchHomeServerName=*)))
(&(objectCategory=person)(objectClass=contact))
(objectCategory=group)(objectCategory=publicFolder)(objectCategory=msExchDynamicDistributionList)
))
Enyhe szépséghiba, hogy mindez kliens oldalon egyelőre nem látszik.
De ráérünk, mert még fel kell tölteni az AD-t szkriptből és ez sem apró feladat. Először is figyelni kell arra, hogy a nemlétező tulajdonság és az üres tulajdonság nem ugyanaz, dacára, hogy lekérdezéskor ugyanazt a választ kapjuk az Isempty() függvénnyel. Habár van valami módszer – lekérdezve az Err értékét -, de nekem ez sohasem működött. Viszont jelen esetben igen fontos rögtön az elején különbséget tenni a két lehetőség között, ha ugyanis egy olyan objektum Exchange tulajdonságának adunk értéket, mely se nem mail-, se nem mailbox-enabled, akkor egy olyan szürke zónába léptünk, melytől minden tisztességes adminisztrátor irtózik. Meg a tisztességtelenek is. A zóna kizárólag a hülyéknek van fenntartva.
Szerencsére van egy másik tulajdonság, melynek mindig van értéke, ha az objektum mail/mailbox-enabled: ez a proxyaddresses tulajdonság. Ez gyakorlatilag egy tömb, amelyben az objektum összes e-mailcíme van felsorolva – márpedig egy darab mindenképpen van neki.
A többi már nem nagy ügy. Még arra kell figyelni, hogy a romantikus nevű MsExchHideFromAddressLists változó értéke hamis legyen – azaz az objektum ne legyen kirejtve a címlistákból.
Mehet is. De még mennyire. És de még hányszor. Eszméletlen eldugott sarkai lehetnek egy 3 fás 6 tartományos erdőnek, zegzugos OU-kal, konténerekkel – márpedig addig kell erőszakolni a szkriptet, amíg a globális címlistával megegyező számú objektumot kapunk vissza. (Igen, megírhattam volna rekurzívnak is. Későn jutott eszembe.)
De végül ez is rendbe jött. Ennek ellenére kliensoldalon semmi változás. A tesztgépen továbbra is a régi címlisták látszanak.
Itt van egy láb, kibe rúgjak? Ki mögött rejtőzködik az MSExchangeAL? A legvégén biztos a System Attendant lesz, de azért durva lenne az egész szervert restartolni egy frissítés miatt.
Miről is írtam az elején? Hogy a listatagság beleíródik az objektumba. Ez egy bulk jellegű írási művelet. Melyik komponens lát el hasonló funkciót? Igen, a Recipient Update Service, a jó öreg RUS. Haza is érkeztünk. Ugyanazt kell csinálnunk, mint amit egy új recipient policy bevezetésekor: minden tartományi RUS-ba bele kell rúgni egy jó nagyot. Figyelem: nagyot. Én úgy tapasztaltam, hogy a hivatalos véleménnyel szemben kicsi rúgásra a füle botját sem mozgatja. (Segítség. Kis rúgás: update. Nagy rúgás: rebuild.)
Egy-két óra várakozás következett, közben volt egy röpke őszülés is: ugyanis befigyelt egy jó hosszú periódus, amikor üres volt a teljes globális címlista. Roppant lehangoló látvány. Szerencsére nem sokan látták, ez ugyanis már péntek éjfél körül volt. Hogy a modemesek mennyit fognak átkozódni, amíg az új offline Address Book-ok leérnek hozzájuk, azt nem tudom. Remélem, nem találnak meg.
Tulajdonképpen most már készen is vagyunk, boríthatják a címeket.
És ha már itt lesznek, át kell túrnom alaposan a tulajdonságaikat, hátha találok valami különbséget, ami alapján automatizálható lehet a listázás.
Link state – hova dugjam?
Life long learning. Ez már csak egy ilyen szakma. Szerencsére.
Jó egy hónapja álltam rá arra, hogy rendszeresen tanulok. A hangsúly a rendszerességen van – tanulni eddig is kellett.
A stratégia a következő: reggel tea felrak, elkortyol, internet átfut (email/feed/link). Utána, amennyiben nyugis nap van, ebédig tanulok. Ha zűrös, akkor csak egy órát. Outlookba jegyzetelek, a végén a levelet hazaküldöm.
Napközben az anyag ülepedik… a vérnyomás meg emelkedik… de ez a természetes.
Este rászánok egy órát és a délelőtt átvett anyagból csinálok egy írott jegyzetet. (Nekem ez jön be – leírni kézzel a vázlatot. Egyetemi vizsgára készüléskor a konyhaasztalunkra készítettem apró betűkkel jegyzeteket. A vizsga előtti napon már úgy nézett ki az asztal, mint egy burda szabásminta: vázlatpontok, nyúlfülek, nyilak. A szép nagy asztalon át lehetett tekinteni az egész tantárgy kapcsolatrendszerét – feltéve, ha a takarítónő nem törölte le közben. De ez igen erősen meg lett neki tiltva.)
Honnan jön a témaválasztás? Több méter könyv gyűlt fel a szekrényemben, ezekkel szép módszeresen haladok. De magunk között szólva, jobban szeretek csapongani – ha a reggeli feed olvasás során találok valamit, szívesen indulok el inkább azon a nyomon.
A napokban futottam rá egy témára és a linkek olyan oldalhoz vezettek, melyet véleményem szerint nem jegyzetelni érdemes, hanem értelmezni, összekapni – lefordítani. És persze elkalandozni. De ha ilyet csinálok, miért ne tegyem a blogban?
Ez merőben újdonság lesz, eddig ugyanis IT témakörben csak szívásokról irkáltam. Dehát mindig azt sulykolják, legyünk proaktívak… nosza.
A téma: routolás Exchange organizációban, azon belül is a link state table környéki problémák kezelése.
Kályha… ahonnan elindulunk: routing group (RG).
Azt gondolom mindenki tudja, hogy az Active Directory leánykori neve Exchange 5.x volt. Itt kisérletezték ki a fiúk a később nagyobb léptékben alkalmazott módszereket. Az összefonódás később is jól látható, az Exchange 200x úgy tapad rá az AD-re mint a kígyók Laookon családjára az ismert szoborcsoporton. Rengeteg átfedés van közöttük és akad analógia is szépen. Egyik ilyen a routing group – site analógia. Nagyjából ugyanaz létezésük oka: információs folyam terelgetése. Site esetén ez a replikáció, routing group esetén pedig a levéltovábbítás. Mindkettőre igaz, hogy egy egységen belül nagysebességű kapcsolattal rendelkező gépeknek illik lenniük – póriasan szólva, az a jó, ha egymásba ér a farkuk.
{kind=link}
Kitérő: Azért nem csak a kapcsolat sebessége szabja meg a csoportosítást. Ha mixed módú organizációnk van, és szeretnénk több administrative group-ot is bevezetni, szomorúan fogjuk látni, hogy mindegyiknek külön RG kell.
A routing group létezésének értelme: csoporton belül a szerverek orrba-szájba kommunikálnak egymással (ugye, a nagy sávszélesség) – csoporton kívül viszont adminisztrátor által szabályozott módon, konnektorok segítségével. (Imádom ezt a szót: konnektor… konnektor. Azannya. Plasztikus. Fogom az egyik végét és feldugom az Exchange szerverbe. A másik végét meglengetem a fejem fölött és beleállítom valamibe, legyen az bármilyen alkalmazás. És ezt tessék szószerint érteni: az Exchange mind a külvilággal, mind saját magával legnagyobbrészt különböző konnektorokon keresztül kommunikál.)
No, tehát vannak routing groupok, melyeket konnektorok kötnek össze. Nincs megkötve, mennyi; nincs megkötve, hány bridgehead szerver lehet. Szabad a pálya. Ellenben minden routing groupban lennie kell egy routing group masternek. Ő az óvónéni. Ő tud mindenkiről mindent; ő terelgeti a leveleket konnektorról konnektorra (egy kis dombra lecsücsülünk, csüccs); ő rak rendet, ha kitör a balhé. Nem fontos, hogy ő legyen a bridgehead – de fontos, hogy tudjon mindenről.
Mi is ez a minden? Nos, a konnektoroknak állapotaik vannak: ezeket hívjuk link state-nek. És van egy táblázat, amelyikben a routing groupok összes link state információja megtalálható: ez a link state table.
Hosszú, de legalább körülményes bevezetőm végén eljutottam végre ahhoz a vadhoz, melynek természete képezi leginkább ezen cikk mondanivalóját. Huh.
Tudjuk, hogy az optimális route útvonalhoz az RG master a következő információkat használja fel: a konnektor költsége, az üzenet típusa, a különböző tiltások. Logikus, hogy ezeknek szintén bent kell lennie a link state táblában – amellett, hogy a konnektor éppen Up vagy Down.
Ha valaki el akar gyönyörködni egy ilyen táblázatban, javaslom, próbálja ki a winroute programot. Aki nem akar elgyönyörködni benne, az ráfaragott, mert a leírt módszerek közül elég sokban kell használni a programot – és higyjétek el, jobb gyönyörködve, jó hangulatban bogarászni, mint fásultan.
Felmerülhet a kérdés, hogy honnan fog tudni mindenről az RG master? Természetesen a member szerverek folyamatosan tömik feljelentésekkel.
- A member szerveren lévő levélkezelő mechanizmus, az ún Advanced Queue (önállóan megérne egy cikket) rányalja a kimenő levélre a legközelebbi hop címét. Az infót a lokális link state táblából veszi.
- A levél visszapattan.
- A member szerver vár max. 10 percet majd feljelenti a konnektort. Jól.
- Az RG master down-ba teszi a konnektort a központi link state táblában majd szétküldi azt a member szervereknek.
- De a member szerverek nem nyugszanak. Sutyiban folyamatosan pingetik a ledőlt konnektort.
- Tegyük fel, hogy a konnektor visszatér a harcmezőre. A member szerverek, mivel pingetik, észreveszik, boldogan üdvözlik és közlik az örömhírt az RG masterrel.
- Az RG master blazírtan újra módosítja a link state táblát és ismét szétküldi.
Az egész kommunikáció a 691-es TCP porton történik. Emellett játszik még a 25-ös is – de ez az Exchange-ben mindenhol játszik, lévén ez az SMTP portja. A routing információk küldözgetéséért a Routing Engine Service, röviden RESrvc felel. (Gyakorlati jótanács: ha újra kell indítani, akkor praktikusabb az IISadmin szervízt piszkálni – ez ugyanis újraindítja az SMTP szolgáltatást is, praktikus sorrendben.)
Mi van akkor, ha pont az RG master dől ki a sorból? Értelemszerűen minden member szerver a lokális link state táblát használja, függetlenül attól, milyen változások történnek a nagyvilágban. Aztán egyszer csak visszajön az RG master – akár megjavítják, akár újat húznak fel, akár kinevezik valamelyiket. (System manager, RG, Members, Server, Set as master) Az új főnök körbenéz a nagyvilágban, gyorsan begyűjti a lokális link state táblákat, lekezeli a feljelentéseket, szétküldi a jó táblákat… röviden szólva asztalra csap és gatyába rázza a macska nélkül cincogó egereket. (Gyönyörű.)
Láthatjuk tehát, hogyan működik egy egészséges rendszer. (Ez olyan, mint az ideális – nem létezik. De állandó cél.) A működés ismerete pedig már fél siker a hibajavításhoz.
Milyen eszközöket fogunk használni:
- Winroute segédprogram. (Igen, mondtam, hogy meg kell szeretni.)
- Felemelt logolás.
- Józan ész. (Valahonnan időben szerezzük be.)
A logolást az Exchange System Managerben lehet állítani, a megfelelő objektumokon. Legalábbis a tankönyvek szerint. Érdekes módon, amikor nagy szar van, mindig bele kell turkálni a registrybe és még feljebb csavarni a logolást. (Az ESM csak 5-ös szintig engedi állítani – pedig a legerősebb a 7-es szint.)
A felcsavarás a következőképpen történik: a registry HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services ágában megkeressük a minket érintő szolgáltatást, azon belül leásunk a Diagnostic menübe, megkeressük a minket érintő eseménycsoportot és 7-re állítjuk az értékét.
Arra azért készüljünk fel, hogy ilyenkor olyan 70 szerzetesnyi sebességel íródik a kódex log.
Nem beszéltem még egy érdekességről. Ha elindítjuk a Winroute programot, láthatjuk, hogy minden routing groupnak verziószáma van, [major.minor.user] formátumban.
Meglehetősen magáért beszélők a nevek, de érdemes egy-két apróságot megemlíteni róluk.
Átfogóan nagy – major – változás viszonylag ritkán történik. Ez alatt leginkább olyan változásokat kell érteni, amikor az AD nyúlkál bele az Exchange lelkivilágába. (Megjegyzés: ha a major index 0, az azt jelenti, hogy nincs link state táblás ökörködés -> azaz vagy csak egy routing group van az organizációban, vagy az illető routing group Exchange5.5 alapú – a jó öreg GWART.)
Közepes – minor – változás általában a konnektorokhoz kötődő változást jelent.
A legutolsó szám – user – változását mindenféle szutyok apróságok okozhatják: WMI piszkálta meg az RG mastert, megváltozott a routing group tagsága, át lett nevezve a routing group, elköhögte magát a szerverszoba egere, stb.
És most akkor lássunk konkrét hibajelenségeket és azok lekezeléseit:
1. A member szerver nem látja mesterét
Bizony, ez baj. A fentiek alapján sejthetjük, hogy ilyenkor a lokális link state tábla dolgozik, valamilyen őskori adatokkal.
A jelenséget könnyen felismerhetjük, elég a Winroute-ban a piros X-ekre koncentrálnunk. Ott találjuk, közvetlenül a szerver(ek) neve(i) mellett.
Mik okozhatják? Csupa triviális dolgok:
- A Routing Engine Service nem fut valamelyik érintett gépen. Vagy fut, csak nem jól.
- Egy gonosz firewall blokkolja a 691-es portot. Ezt telnettel tudjuk ellenőrizni.
Emellett konkrétan azt is meg tudjuk nézni, hogy mi a helyzet a 691-es porttal a szervereken. A ‘netstat -a -n’ parancs megmutatja, mely portjaink nyitottak és merrefelé. Member szerver esetén látnunk kell egy kapcsolatot az RG master felé – RG master esetén látnunk kell egy-egy kapcsolatot minden member szerver felé. (Pontosabban, nem csak egyet, két szerver több szálon is kapcsolódhat.) - Okozhat problémát a computer felhasználó hibás autentikációja is. (Logikus – ilyenkor a számítógép kiesik a haveri körből.) Érdemes átnézni az eventlogot. Ugyanitt fogjuk megtalálni a transzport hibára utaló jeleket is. (Event kód: 961/962)
- Elveszhet a bűnös szerver ‘Send as’ jogosultsága. (Elég cifra jogosultsági rendszerben vannak a szerverek; a domainprep létrehoz nekik néhány csoportot és ezekre beállít egy default jogosultságot. Elég könnyű ezt a rendszert felrúgni – bőven elég, ha átrakjuk a csoportokat egy másik OU-ba. Tesztelve.)
A nyomozáshoz a Microsoft a Regtrace programot ajánlja. Én is ezt tenném a helyükben, tekintve, hogy ez egy nagyon praktikus program – nekik. Mezei halandó sajnos nem tud vele mit kezdeni. (Szépen le van írva, hogyan kell elindítani, hogyan kell paraméterezni, egyáltalán hogyan monitorozza a program a történéseket, miközben reprodukáljuk a hibát, szépen le van az is írva, hol találjuk az eredményként kapott bináris fájlt és hogyan kell azt elküldeni a PSS-nek visszafejtés céljából.) - Lehet, hogy a szerver rossz nevet használ a bemutatkozáskor. Elismerem, ez annyira azért nem triviális ok. A szerverek az ún. ServerPrincipalName (SPN) értékkel azonosítják magukat a routing groupban. Ez az érték a szerver Network Adress attribútumának ncacn_ip_tcp változójában tárolódik, megtekinteni illetve módosítani ADSIEdit-tel vagy LDP-vel lehet. Kicsit háklis banda ez a routing group, csak akkor fogadják el a bemutatkozást, ha FQDN formájú a név. Netbios név, IP cím nem megfelelő. Olyan ez, mint a nyakkendő az elit mulatókba.
- Az, hogy a többiek nem ismerik fel a bűnös szervert, sokféle okból következhet. Lehet jogosultsági hiba, lehet bemutatkozási hiba – és lehet Kerberos autentikációs hiba, mondjuk egy lejárt computer jelszó miatt. Ekkor célszerű az NLTEST segédprogit használni. (Ez igaz általánosan is, minden olyan esetben, amikor netlogon hibára gyanakszunk.) A program használatáról van egy jó leírás. Röviden annyi, hogy el kell indítani a megfelelő paraméterrel – mely paraméterek egy szép nagy táblázatban találhatók és arra vonatkoznak, hogy mire vagyunk kíváncsiak – majd újraindítjuk a Netlogon szolgáltatást és megnézzük, mi került a %windir%\debug\netlogon.log fájlba.
- Természetesen DNS. Ezt talán mondanom sem kellett volna. Ha a szerverek eltérő tartományokban vannak, meg kell nézni, rendesen megy-e a névfeloldás. A magam részéről megnézném akkor is, ha azonos tartományban vannak. Fontos, hogy a virtuális SMTP szerveren található FQDN megegyezzen a DNS-beli FQDN-nel.
- Legvégül érdemes elgondolkodni, nem vezettünk-e be mostanában valami elkefélt GPO-t, mely esetleg belepiszkálhatott a korábban részletezett folyamatba.
2. RG mesterek háborúja
Megjelenik a sötét oldal.
Egy routing groupban az az RG master, akiről a szerverek fele+1 szerver azt állítja. Ezt a member szerverek ún. link state attach információk küldözgetésével beszélik meg. Értelemszerűen egy szervernél ő maga lesz a főnök – azaz alaphelyzetben mindig az elsőnek telepített szerver az RG master. Az is marad, amíg az adminisztrátor másképp nem rendelkezik.
Mikor tör ki a háború?
- Például akkor, ha az adminisztrátor úgy léptet elő RG mesterré egy gépet, hogy az öreg mestert nem lépteti vissza.
- Az egyik member szerver megőrül és hamis információkat kezd terjeszteni.
- Hálózati hibák következtében nem érnek célba a link state attach információk, miközben főnökváltás történt.
Mi lehet a teendő? Először is megvizsgáljuk a hálózatot, mennyire atombiztos. Elérhetők-e azok a bizonyos 691/25 portok? Megy-e az AD replikáció? Nem rágta-e el a patkány a vezetéket?
Másrészt magunkba szállunk és végiggondoljuk, nem töröltük-e pusztán szórakozottságból azt az Exchange szervert, amelyik eddig az RG master volt? Esetleg nem léptettünk-e elő egyet úgy, hogy még a régi is megvan?
Ha ez utóbbi esetek egyike történt, akkor az ADSIEdit vagy LDP programokkal gyorsan korrigálhatunk, az üzemzavart meg ráfoghatjuk a napfolt tevékenységre. (Itt található egy írás, hogyan állítható vissza egy véletlenül kigyapált routing group. Azért ne próbáljátok ki éles rendszeren.)
3. Van olyan routing group, amelyik nincs
Felmerülhet a kérdés, hogy ha nincs, akkor hogyan látjuk. Nos, például a Winroute segédprogramból. Mutatja, hogy itt kérem van egy routing group, de a fene se tudja, hogyan hívják és mi ez.
Mondhatnánk, hogy a francot sem érdekli, nem kér enni. Csakhogy ott van. Érvényes routing információkkal. Hogy neki vannak konnektorai. Balszerencsés esetben egészen olcsók – és ilyenkor ebbe az irányba próbálnak menni a levelek. Mely irány nem létezik.
Nyilván törölni kell… de hogyan? Hiszen nem létezik!
Farkába harapott a kígyó.
Ravasz trükkök vannak a rendrakásra.
- A legelső, hogy megnézzük, olyan felhasználóval vagyunk-e belépve, akinek legalább olvasási jogai vannak az AD konfigurációs névterében? Ha olyan a felhasználó, be tudott-e rendesen lépni? Ha belépett, eléri-e a konfigurációs névteret? Tudom, triviális… de egy autentikációs hiba miatt egyszer kis híján megőrültem egy hasonló szituációban.
Általában is az egyik legfontosabb hibafelderítési lépés meggyőzödni, hogy egyáltalán fennáll-e a hiba… nem az észleléssel van-e inkább gond? - Nos, benne vagyunk az Atyauristens csoportban, közvetlenül az RG master gépen futtatjuk a Winroute-ot, mégis látszik, aminek nem lenne szabad látszódnia. Erre mondják azt városiasan, hogy kaki van a ventillátorban. (A póriast most inkább hagyjuk.)
A helyzet az, hogy valószínűleg egy törölt routing group-ra vonatkozó bejegyzés beragadt a link state táblába – és a RESvc képtelen kitörölni. Az egyetlen megoldás a tabula rasa – kezdjünk mindent előlröl. Választhatjuk azt is, hogy újratelepítjük az összes Exchange szervert (nemröhög – a Microsoft eszköztárában szerepel ez a lehetőség is), de szerencsére van egy egyszerűbb megoldás is: a bűvös újraindítás. Némi kényelmetlenséget okoz, hogy az organizáció összes szerverét kell egyszerre újraindítani, úgy, hogy először mindenhol az RG master gépek álljanak fel. Kényelmetlen, de ha worldwide organizációnk van, akkor itt a lehetőség néhány potya repülőjegyre. - Az előbb hazudtam, de csak a drámai hatás kedvéért. Van egy másik lehetőség is: felhergelhetjük a REMonitor segédprogramot, hogy injection módban működjön. Erről igen jó cikket írt az Exchange gárda, én itt csak összefoglalom.
Először a rossz hír: a program nem tölthető le szabadon, a Support-tól kell igényelni. Ha megvan, akkor első lépésben be kell állítani a futtatásához szükséges jogosultságot. A fiúk elég sokat vacakolnak ezzel, végül arra jutnak, hogy a legegyszerűbb, ha trükkös módon a local system account nevében futtatjuk. Ez – gondolom – ismerős. Beidőzítünk egy command prompt-ot és az a local system account nevében fog elindulni. Nos, itt csak annyi a probléma, hogy távolról ütemezve a taszkot, az a konzolon fog promptot adni. (Windows2003 esetén no problemo, az ‘mstsc /console’ kihúz a bajból.) Azért nálunk valamivel mások a viszonyok… feltételezem, minden Exchange adminisztrátor azzal kezdte a tevékenységét, hogy az Atyauristen felhasználónak visszaadta a “Send as”/”Receive as” jogokat – ez meg éppen elég a program futtatásához. (Jaj, ne üssenek… nem mondtam semmit…micsoda?… három év vasban?…)
Ha rendeztük a jogosultsági matyit, akkor végre elkezdhetünk dolgozni. Bemásoljuk a progit a bin könyvtárba, elindítjuk. Kedvesen közli, hogy mely fázisnál jár, mit talált… majd vége.
Mit is csinált?- Ha talált beazonosíthatatlan routing group-ot, törölte belőle a szerverek és konnektorok bejegyzéseit.
- A routing group-hoz tartozó névterek címeibe belebiggyesztette a ‘deleted’ kifejezést.
- A major indexet megnövelte eggyel.
Ezzel sikeresen elérte, hogy egyrészt efelé a routing group felé soha a büdös életben nem fog levél kóvályogni, másrészt a link state table is lecsökkent valamelyest – ami nem hátrány nagyméretű organizációk esetében.
Amit viszont nem ért el, az az, hogy nem tűnik el a rosszindulatú routing group bejegyzés a táblából. Sajnálatosan ezt csak az újraindításos módszer biztosítja.
4. Egy ledőlt konnektor üdének, frissnek látszik
Ilyesmi is előfordulhat. Mondanom sem kell, elég ciki, amikor szembesülünk a ténnyel, megtekintve a Winroute listáját.
Pedig simán előfordulhat.
- Olyan konnektorunk van, amelyiknél bizonytalan a hídfőállás létezése. Akkor fordulhat ilyesmi elő, ha a konnektorunk pl. DNS-t használ ahhoz, hogy a következő hop-ot meghatározza. Tipikus példa erre egy SMTP konnektor, amelyik nem smarthost-hoz kapcsolódik.
Megjegyzés: Amikor azt írom, hogy SMTP konnektor, mindig kicsit zavarban vagyok – mert eszembe jut, mennyit agyaltam anno, hogy mi is az a virtuális SMTP szerver és mi is az az SMTP konnektor és tulajdonképpen milyen viszonyban is vannak ezek? Fóti Marci gondolatát beépítve imhol egy plasztikus kép: van az SMTP szolgáltatás, mely tetszőleges számú virtuális SMTP szervert képes üzemeltetni. Az SMTP konnektor pedig tulajdonképpen a virtuális szerverekre vonatkozó SMTP policy.
De akkor is előfordulhat ez a jelenség, ha az ún Routing Group konnektornál (RGC) a forrás bridgehead rovatba az <any> opciót hagyjuk bent. (Nem akarok most kitérni az egyes konnektor típusokra, mert a cikk lassan kezd fárasztó lenni. Nekem legalábbis meglehetősen.)
- Smart host esetén sem vagyunk teljesen biztonságban, ha nemrég állítottuk át a távoli bridgehead szerver paramétert.
- A konnektorunk Exchange5.5 verziójú konnektor vagy a konnektor egyik hídfőállása 5.5-ös szerver. Már tudjuk, ekkor nem játszik a link state table.
5. A konnektor bungee-jumping-ot játszik
Azaz meglehetősen nagy frekvenciával hol ledől (down), hol feláll (up). Lehet, hogy ez egy kellemes szórakozás a konnektor számára, de elég sokba kerül az Exchange rendszernek. Ugyanis a konnektor minden egyes állapotváltása bősz kommunikációt indít el a member szerverek és az RG master között, mire berendezik a megváltozott állapotnak megfelelő link state táblát. Aztán mire befejezik, az a hülye konnektor megint ugrik egyet.
A szóbajöhető okok:
- Zavar az erőben, a network hülyéskedik. Netmon, vagy Ethereal… izé Packetyzer. Kinek melyik a szimpatikusabb.
- A konnektorok alatt dübörgő protokoll bolondul meg. Összeakadnak az X.400 protokoll rétegei. Egymásba gubancolódnak az SMTP protokoll alsóbb rétegeiben lévő lábai. A Microsoft szerint ez leginkább a külső fejlesztésű implementációknál fordul elő. Naná.
A megoldás ebben az esetben is Netmon és barátai.
Illetve létezik egy átmeneti megoldás, úgynevezett körbedolgozás. Van egy patch… mely valamit csinál. Sajnos, hogy mit, az nem derül ki. Csak az, hogy ilyen esetekben tegyük fel.
Pontosabban, eredetileg arra találták ki, hogy amikor Exchange5.5-ről frissítettünk Exchange2000-re és a nagyméretű rendszerinformációs forgalom (ORG_INFO) megakadályozza a levélküldést a lassú vonalon, akkor toljuk a képébe a foltot. Feltételezem, valahogy cseppekben adagolja a változásokat.
Élesebb szemű olvasók valószínűleg észrevehették, hogy itt nem ez a szituáció forog fenn. De ez egy remek folt, most is használhatjuk, csak bele kell túrni egy kicsit a registry-be. (Már vártam.) A HKLM\SYSTEM\CurrentControlSet\Services\RESvc\Parameters alatt kell létrehozni egy AttachedTimeout nevű dword kulcsot, majd értékének beírni egy szimpatikus számot 1 és 604800 között. Nem mondhatjuk, hogy nem kaptunk elég teret fantáziánk kibontakoztatásához.
Nos, a végére értem.
Akit ennél is mélyebben érdekelnek a routolási furfangok, itt talál egy remek letölthető könyvet a témáról.
REMonitor
Egy újabb rémálommal kevesebb.
Emlékszem, amikor először találkoztam ilyesmivel, nem hittem a fülemnek.
Egy nagyobb migráció után Exchange routing group-okkal zsonglőrködtem egy meglehetősen nagy organizációban. A végén minden beállt abba az állapotba, amilyenben lennie kellett. Szerintem.
Csak éppen nem tűnt el egy kitörölt routing group – emiatt a levelek véletlenszerűen félrementek. Jó lett volna ténylegesen is megszabadulni a rossz routing group-tól… de még flex-szel sem tudtam eltávolítani. Egy idő után feladtam, call PSS. Azt mondták, igen, elő szokott ilyesmi fordulni, a routing információk cache-ben vannak és néha beragad valami szemét. Ki kell üríteni a cache-t.
– Oké – mondtam – csapjunk bele… hogyan kell?
– Nagyon egyszerű – mondták – az összes szervert le kell állítani egy időben.
– A routing groupban?
– Nem. Az egész organizációban.
Ekkor ültem seggre. Nem kis munka volt megszervezni, hogy minden helyszínen legyen egy ember, aki adott jelre (mobiltelefon) lekapcsolja a szervereket majd adott másik jelre visszakapcsolja. Távoli újraindításról szó sem lehetett, mert addig mindegyik gépnek kikapcsolva kellett lennie, amíg a routing master Exchange szerver fel nem állt.
Viszont ettől tényleg megjavult a levelezés.
Azért úgy belegondoltam, hogy mondjuk egy multicégnél, ahol garmadával vannak szerverek különböző kontinenseken, mekkora meló lehet egy ilyen akciót megszervezni.
Valószínűleg belegondolt a Microsoft is, mert kihoztak végre egy eszközt, mely kezeli ezt a problémát. Az a neve, hogy Routing Engine Monitor (REMonitor) és az Exchange Team szépen le is írja, hogyan kell kezelni. A logika azt mondatja velem, hogy nagyon jó eszköznek kell lennie, ha ennyi időbe tellett a kifejlesztése.
Kész katasztrófa
Tegnap egész nap BRS teszten voltam. Ez gyk. katasztrófa utáni visszaállítás teszt, időre. Kimegy egy talicska informatikus egy isten háta mögötti telephelyre(1) és megpróbálja lemezekről, szalagokról visszaállítani az éles rendszert. Izgalmas foglalkozás.
Először is megkérnék mindenkit, hogy az elkövetkező napokban finoman, nőiesen beszéljen velem, mert káromkodásból egy hónapra fel lettem töltve. Köszönöm.
Az én feladatom egy kulcsfontosságú Exchange szerver visszaállitása volt. Bármennyire szűk is ilyenkor az idő, szoktunk azért kísérletezni is. Most például kipróbáltuk, mennyire járható a /disasterrecovery kapcsolós visszaállítás, élesben. (Annak ellenére játszottunk vele, hogy van teljes mentésünk az Exchange szerverről.)
Na szóval, nyers szerver felugrott, particiók/könyvtárak beállítva, régi gép eltávolítva a tartományból, új gép beléptetve, jöhet a szerver telepítés. Next-next-nekemnepofázz-finish,… hűdegyors volt ez a telepítés. Nem is rakott fel semmit, csak egy dll-t. Újabb próba, most már le is nyitogatva a menüpontokat,… hát, azt mondja, hogy a prerekvizitek nem stimmelnek. És tényleg, teljesen kiment a fejemből, hogy az Asp.net és a Pop3 szervízek telepités után manuálba kerülnek. Elindítottam őket, de továbbra is hibaüzi jött, amikor ki akartam választani a kollaborációs komponenst. Jó, akkor szedjük le ezt az elb… izé, nyomorult telepítést. Nem jött le. Még a szerver csodálkozott a legjobban; azt mondta, hogy némá, milyen vicces, váratlanul nem tudom leszedni ezt a komponenst.
Jó. Újratelepítés. Sittysutty megvolt. Hoznám létre az adatbázisok könyvtárait, amikor látom, hogy teljesen össze vannak borzolva a partíciók. Visszanevezés közben jött a hidegzuhany: az E partíciót nem lehet átnevezni, mert az lett a system. Miaf? Ez még akkor is durva, ha tudjuk, hogy a system partíció az, amelyikről bootol a rendszer, a boot partíció pedig az, amelyiken a system van. És tényleg, az E particion ott figyelt a boot.ini. Hajjaj. Újratelepítés, de most még a szöveges setupnál töröltem mind a nyolc partíciót – így nem tudott hibázni a kedves. Ez a telepítés már teljesen olajozottan ment, öröm volt nézni. Nem volt egy felesleges mozdulatom sem. Illetve volt – egy beintés, amikor megint nem volt hajlandó települni az Exchange. Nagyítóval néztem át a prerekvizit listát, de minden klappolt, az utolsó szögig. Lassan már eljött az ideje abbahagyni a kísérletezést, de szerencsére a fájlszerver visszatöltés lefoglalta a szalagos egységet, tehát próbálkozhattam még egyszer. És ismét rámmosolygott a google power, egy link eréjéig.
Érdemes idézni:
I called Microsoft Product Support and their solution was to uninstall 2003 Server SP1, install Exchange, install Exchange SP1 then install 2003 Server SP1. This sounds far too shaky a solution for me and on my front-end servers I installed 2003 Server slipstreamed with SP1, so, since I’m the position to do it, I’m just reinstalling the servers from scratch without SP1 until I have Exchange installed.
Nos, erre nem számítottunk; nem volt nálunk külön Windows2003 szerver telepítő cédé, külön felrakható SP1-gyel. Odamentem a konzolhoz és megtippeltettem a kollégával, hogy vajon mit fogok most csinálni. Fogalmam sincs, honnan találta ki elsőre, hogy szervert fogok újratelepíteni. Amíg a bitek tepertek a vasra, nekiálltam leszedni az Internetről az Sp1-et. Aki netán elfelejtette volna: ez a dög 330 MB. Nem kicsit bonyolította a dolgot, hogy idén újítottunk: nem vittünk laptopot, desktopot; ehelyett az ügyfél unixosaitól kaptunk egy-egy Kanotix Linux live distro cédét. Erről tetszőleges vasat be tudtunk bootolni – volt egy csomó, egymásrahajigálva a sarokban – és rdesktop-pal már csűrtűnk is fel a szerverekre. Töredelmesen beismerem, az ikszre végződő nevű rendszerekben nem vagyok nagy spíler, így okozott némi nehézséget, az Sp1 terelgetése. Windowsban azt csináltam volna egy vinyó nélküli gépnél, hogy bemeppeltem volna K: meghajtóként a szerver valamelyik megosztását és arra töltöttem volna le böngészőből a stuffot. Ez itt nem jött össze. SMB-n tudtam ugyan kapcsolódni, de letöltéskor nem tudtam megadni ezt a kapcsolatot. Végül leszedtem a csomagot ramdiszkre (hálistennek volt bőven), onnan krusader-rel ment tovább a szerverre. (Sorry, MC-vel nem sikerült.) Mindenesetre, amíg a memóriába tőtikézte lefelé a fájlt, addig csak lábujjhegyen mertem közlekedni a szobában.
Közben felment a Windows2003 szerver is, Sp1 nélkül. Ránézésre egy csomó rendszerkomponenst nem ismert fel, driverek meg nem voltak, de úgy döntöttem, nem is kellenek. Ha száguldozni akarok egy autóval, akkor nincs szükségem karosszériára. Ugyan már kilométerekre kerültünk attól az elvtől, hogy a visszaállítandó rendszerhez minél hasonlóbbat állítsunk össze – de amikor a hasonlóságra törekedtünk, az nem jött be. Na, mindegy, a kasztni nélküli cucc beröffent. Ment rá az új install. És nem volt inkompatibilitásra utaló hibaüzenet az Exchange setup indításakor! Elégedett mosoly… de nem. Megjött ugyanaz a nyomoronc 0xC007003A(58) hiba.
Újabb varázslások következtek. De tényleg. A mosoly egyre görcsösebb lett az arcomon. Holnap ITIL vizsga. Közben nemhogy a mai tanulásnak, de a mai lefekvésnek is egyre biztosabban lőttek.(2)
Átnéztem a DNS-t és ott virított benne egy hasonló nevű gép. Ki a lilafaszom tette ezt bele? Nyess. De ettől sem javult meg semmi. Oké. Netdiag. Nagy büdös Kerberos hiba. WTF?! Aszongya nem tudja autentikálni a gépet – de névként a hasonló nevű hostot nevezte meg. Mivan? Valami derengeni kezdett, rátekertem a gépnév rovatra. Basszus. Az eredeti gép nevében szerepelt egy ‘0′ karakter. A nagy kapkodásban megszokásból magyar kiosztásúként használtam egy pillanatra a konzolbillentyűzetet, és nulla helyett a felsőfütyi karaktert tettem be. Az oprencer meg volt annyira intelligens, hogy sem ezt a karaktert, sem az utána következőket nem vette figyelembe. Esetleg figyelmeztetni? Ugyan már. A figyelmeztető csapat az összes aktivitását kiélte akkor, amikor a nem használatos desktop ikonokról volt szó – másra már nem maradt lendület.
Gép kilép/belép, közben átnevez, AD reset. De ettől sem jutottunk előre. Jobb híján rászálltam a Kerberos hibaüzenetre, de semmire sem jutottam vele. Pontosabban annyira, hogy csaltam és megkérdeztem az éles rendszeren dolgozó kollégát telefonon, hogy nézze már meg, az éles szerveren – mely játszásiból most ugye le volt bombázva – mit mond a netdiag. És azon is ott volt a Kerberos hiba.
Tehát ez rossz nyom.
Itt érkeztünk el egy döntési ponthoz. A felkészülési dokumentációk egyik része azt írta, hogy az Exchange /disasterrecovery előtt töltsünk vissza system state mentést. Másik része meg meg sem említette ezt a lépést. Nekem ez utóbbi tűnt logikusnak, hiszen arról szól a történet, hogy _csak_ adatmentés van – az Exchange paraméterek majd az AD-ból fognak visszajönni.
Ötlet híján csapást váltottunk: jöjjön az a system state. De majd csak másnap reggel.
Új nap, új remények. De hamar kiderült, hogy a világegyetemben minden változik, csak a szívás állandó. Akkora volt a hardver különbség a két gép között, hogy képtelenség volt rá visszatölteni a system state mentést.
Ekkor járt le az időm. Visszatértünk a jól bevált Exchange visszaállítási módszerre, hanyagolva az új utakat.
Kár érte, mert reméltem, hogy ennél a visszaállítási módszernél meg tudjuk kerülni az adatbázisonkénti hét órás konzisztencia ellenőrzést.
(1) Csak úgy megjegyzem, hogy ez egy nagyon nagy nevű cég direkt erre a célra felingerelt telephelyén zajlott. Nem csak mi használjuk ezt a szájtot, az ügyfelünkön kívül sokan mások is igénybe szokták venni. Pontosan tudom, hogy kik, ugyanis a nagynevű cég emberei csesztek bezárni a dokumentációs szekrényt. Pusztán unaloműzőként lehetőségem volt áttanulmányozni néhány nagy magyar cég informatikai rendszereinek a leírását.
(2) Yes; hajnal kettő lett belőle.
A nagy levélelkapó manó
Mottó:
A patkó miatt a ló elveszett,
A ló miatt a lovas elveszett,
A lovas miatt a csata elveszett,
A csata miatt az ország elveszett,
B+ nézd már meg jobban azt a patkószeget.
A patkó miatt a ló elveszett,
A ló miatt a lovas elveszett,
A lovas miatt a csata elveszett,
A csata miatt az ország elveszett,
B+ nézd már meg jobban azt a patkószeget.
Bevezetés:
Nagy ügyfélnek van egy nagy Exchange organizációja. Van neki két kisebb, többé-kevésbé független leányvállalata. Ezek szintén benne vannak az organizációban, saját Exchange/DC szerverekkel. Az egyik leánnyal nincs is gond, az ő szervereiket mi üzemeltetjük. A másik viszont zűrösebb, elméletileg semmi közünk sincs a gépeikhez – gyakorlatilag muszáj bele-belenyúlkálnunk. Persze a saját adminjaik is bele-belenyúlkálnak.
A nagy ügyfélnek van saját levelezési internet kijárata.
A leányvállalatnak önálló routing groupja van, de az Exchange-t csak belső levelezésre használták. Kifelé saját linuxos levelezési rendszert építettek ki. A kettő között nem volt átjárás.
Megkérték, hagy használhassák külső levelezésre is az Exchange-t. Beállítottam az organizációban, hogy a továbbiakban érezzen felelősséget az új emailtartományért (kaptak egy email policyt), szóltam nekik, hogy írassák át az MX rekordjukat és elmentem nyaralni külföldre.
Csakhogy ők kreatívan értelmezték a lehetőségeiket, ugyanis felraktak egy új smtp konnektort a saját tűzfaluk és Exchange szerverük közé majd erre iratták át az MX rekordot. A konnektoron 1-es súlyt állítottak be (naná!), ezzel sikeresen magukra rántották a nagy testvér teljes kifelé menő levelezését. Ez még nem is lett volna olyan nagy gond – de nem sokkal később lekorlátozták, hogy csak ők használhassák a konnektort. Ekkor állt le a nagy cég levelezése és tört ki a botrány. Kollégáim hosszas munkával kinyomozták, mi történt, felemelték a kalózkonnektor súlyát, a levelezés megjavult. Persze felelőst kellett találni. A leányvállalat elegánsan mindent rám fogott, mondván, hogy én csináltam a konnektort. Sőt, már a nyomozás kezdeti fázisában is mosták kezeiket, mind a nagy cégnek, mind a kollégáimnak azt állítva, hogy én csináltam mindent. Emiatt sokáig mindenki azt hitte, hogy ez a konnektor teljesen legális és jól van konfigurálva.
Amikor visszajöttem a nyaralásból, találtam néhány ejnye-bejnye levelet a postafiókomban. Marhára nem értettem a dolgot. Tiszta szerencse volt, hogy éppen nem akadt túl sok munkám, így megpróbáltam utánajárni a leveleknek. Lefényképeztem néhány képernyőt, megmutattam mind a főnökeimnek, mind a nagy ügyfélnek, hogy itt akkor történt a disznóság, amikor külföldön voltam. Ezzel rendeződött is a helyzet. (Mindenesetre akár örülhetnék is, hogy annyira jól fekszem mind az ügyfélnél, mind a saját cégemnél, hogy egy ekkora – nekem tulajdonított – malőrt tkp egy ejnye-bejnyével úsztam volna meg.)
Cselekmény:
Jött egy bejelentés, hogy a leányvállalat és a nagy cég között megszűnt a public folder replikáció. Tudjuk, hogy a replikáció levelek útján történik – tehát első dolgunk benézni a Message Trackingbe, hogy mi a helyzet. A PF replikáció az Exchange szerverek Information Store (IS) szolgáltatásai között zajlik, ők leveleznek egymással. Az IS-ek email címei így képződnek: Servername-IS@domain.root. Erre kell rákeresni a logban.
- Kitérő:ezzel azért óvatosan kell bánni. A Message Tracking azt a címet mutatja, amelyik a borítékon belül(!), azaz a levél data mezőjén belül van. Csakhogy a levelezés az alapján a cím alapján történik, amelyik a borítékra van írva – és ez a tracking logban nem látszik. Jártam már úgy – pont ennél a cégnél -, hogy installálás után az IS nem kapott email címet, emiatt nem ment a PF replikáció. A tracking log azt mutatta, hogy a levél jó címre ment ki: a data mezőben ott is volt a jó cím; csakhogy a nem látható ‘rcpt to’ üres volt. Az event log és az Archive Sink mondta meg végül az igazat és az AdsiEdit-tel írtam be a jó emailcímet az IS adatai közé.
Visszatérve a mostani szituációhoz. Szépen látszott, hogy a nagy cég szervere elküldi a replikációt indító levelet a leányvállalatnak és nem kap választ. Nocsak. Korábban már írtam, hogy kényszeres telnetelésben szenvedek. Beléptem a leányvállalat szerverére, telnettel küldtem egy levelet a nagy cégnél lévő postafiókomba és megnéztem a levél tulajdonságlapján, milyen úton jött meg. Jól sejtettem, körbement: nem a két routing group közötti konnektort (RGC) használta, hanem kiment az internetre a leány kapuján és bejött a nagy cég internet kapuján. (Ídes babám, engedj ki, hagy jöjjek be!)
Nézzünk be a System Managerbe. Azt mondja, nincs hozzá jogom. Nekem?! Az Exchange Atyaúristen nevében voltam belépve: enterprise admin, domain admin, localadmin, schema admin. és ennek nevében történt az organizáció létrehozása is. Szóvá is tettem a legközelebbi összeröffenésen a leánycég vezetőinek, hogy ugyan miért rúgtak ki a szerverükről? Harsány tiltakozás, persze – dehát nekik ekkoriban volt némi szavahihetőségi deficitjük.
Mindenesetre az adminjukkal nekiugrottunk a rendszernek és tényleg nem volt egyszerű a helyzet. A DC-n belépve tudtam menedzselni a felhasználóikat. Ő az Exchange szerverre belépve el tudta indítani a System Managert és látszott, hogy a routing group-on megvan a full admin jogom. Meg lefelé is mindenhol. Ha én léptem be, még az ADUC-ot sem tudtam elérni.
Hmm… elvonultam gondolkodni.
Engem igazából a Winroute érdekelt volna, megnéztem: azt mondta, ismeretlen organizáció és egyáltalán, minden ismeretlen. Nocsak, nyomon vagyok? Nézzük, mi van az AdsiEdittel – itt sem értem el a tartományt. Ldp? És igen – az ldp-vel sikerült végre kapcsolódnom a tartományhoz. Tesztként átírtam egy felhasználó emailcímét, működött. Mit tudhat az ldp, amit az MMC illetve az AdsiEdit sem tud? Fogalmam sincs. Nézzük meg Netmonnal. (Pontosabban elsőre Ethereal-lel ugrottam neki, de az nem tudta értelmezni az LDAP forgalmat. (??))
Először az RST-kre figyeltem fel és csak később esett le, hogy némá, az Exchange szerver a forest root DC-vel akar ldapozni. Vajon minek? Mindkét tartományi DC GC is egyben – elméletileg le kellene tudniuk kezelni azt a helyzetet, hogy a felhasználó a forest rootban lett létrehozva. Bár a szituáción lehetett volna egy csomót agyalni, de az egyszerűbb utat választottam, írtam egy levelet a tűzfalasunknak, hogy léccilécci engedd már át az ldap-ot e két gép között. És innentől működött minden adminisztrációs eszköz. (Mondjuk továbbra is érdekelne, miért volt ravaszabb az ldp, mint a többi.)
Persze a PF replikáció az nem javult meg.
Átnéztem jól az organizáció routolását, hangolgattam is, végül ez lett:
InternetN(SMTP)(2) – (2)(SMTP)Nagycég(RGC)(1) – (1)(RGC)Leány(SMTP)(2) – (2)(SMTP)InternetL
Ennek működnie kellett volna, különösen, hogy az RGC-nek kutya kötelessége lett volna a belső leveleket szállítania, függetlenül az SMTP konnektoron lévő súlytól. Kínomban írtam az MS TAM-unknak, ugyan szerezzen már valami anyagot arról, hogy hogyan működnek testközelből ezek a konnektorok, különös tekintettel arra az esetre, amikor egyszerre van RGC és SMTPC – ugyanis ilyen szituációról a Resource Kit sem tett említést. Visszaírt, hogy ennek így tökéletesen kellene működnie, itt más lesz a gáz. Beszélt Mészáros Kornéllal és küldtek egy checklistát, mit nézzek át. És igen, itt lett nyakoncsípve az aljas: a virtuális SMTP szerveren is be volt állítva egy smarthost – a leánycég internetkijárata előtti spamszűrőre célozva. Amikor csinálták az illegális konnektort, nem bízták a véletlenre, beállították itt is – ezáltal nemcsak azok a levelek mentek az SMTP konnektor felé, melyeknek arra kellett volna menniük, hanem mindegyik. Ugye milyen egyszerű, mi? Csak meg kellett volna nézni azt a nyomorult patkószeget.
A fiúk persze elfelejtették a beállítást és hagyták, hagy szívjak vele pár napot.
Persze, ha nem így tesznek, szegényebbek maradtunk volna ezzel a cikkel.
Apu hod med be
Rendszeresen hallani olyan esetekről, amikor nem figyelt oda az Exchange adminisztrátor és az adatbázis mérete átlépte a bűvös 16 GB értéket. (Pedig a problémát meg lehet előzni: írni kell egy wmi szkriptet, beidőzíteni napi egyszeri futásra. Ez azt csinálja, hogy ha az adatbázis mérete nagyobb, mint 15 GB, akkor mondjuk pirosra váltja a háttérképet. Ha nagyobb lesz, mint 16 GB, akkor meg postázza az admin munkakönyvét.)(1)
No mindegy, megtörtént a baj, mit lehet ilyenkor csinálni? Nyilván offline tömörítés, törlés, offline tömörítés gyógyítja a túlsúlyt… de nem biztos, hogy erre pont az az időpont a megfelelő, amikor az adatbázis elment kávézni. Mit nem adnánk ilyenkor egy kis haladékért?
A jó hír az, hogy létezik ilyen haladék. Természetesen registry turkálással aktivizálható. (A magam részéről utálom ezt a technikát. Ebből származnak azok a mítoszok, hogy registry buherával mindent meg lehet csinálni. Hogyan lesz a Windows szerveremből kenyérpirító? Írd be ezt meg ezt a registrybe…)
A matatás előfeltétele, hogy vagy Exchange 2003 legyen a szoftver vagy 2000 alatt legyen felugratva a post service pack 3 rollup. A beállítás után újra kell indítani a gépet és máris kaptunk plusz egy gigát. Ja, és mit kell beírni? Itt van a KB cikk.
Oké. Most nézzük, mi van akkor, ha standard Exchange szerverünk van, nem akarunk enterspájzot, de az adatbázisunk mérete rakétaként szárnyal? Probléma szál se, tiszta szerencse, hogy műveltek vagyunk. Például tudjuk, hogy az Exchange 2003 SP2-ben a méretkorlát felugrik 75GB-re. Ez a csomag ugyan még nincs kint, de a béta verzió már igen és a korlátfeloldást ez is tudja. Azaz ha nagyon szorongat az ügyvezető és átvállalja a béta kockázatát (MS természetesen nem ajánlja), akkor meg lehet próbálni ezt az utat.
Csakhogy. Feltettük, az adatbázis átvágtatott a 16 GB célvonalon és eldőlt. Ilyenkor mi van?
Szokásos trükk. A méretkorlát feloldása nem automatikus. Vajon hol lehet bekapcsolni? Úgy van. Registry. I like this company.
Kellemes mellékhatás, hogy az SP2 után létezik egy másik paraméter is a registryben – ezzel figyelmeztető értéket lehet beállítani az adatbátisméretére.
Mindez szépen le van írva az Exchange csapat blogjában.
[Update]
(1) Gömöri Zoli szólt, hogy ő már írt egy ilyen szkriptet. Íme.
Én a magam részéről egyszerűbbre gondoltam – szvsz. elég lehet fájlszinten lekérdezni az .edb/.stm méreteket – bár így sem rossz.
A lehetetlenre egy kicsit várni kell
Úgy kezdődött, hogy Ügyfél egyik középvezetője nem tudta összeszinkronizálni Sony-Ericsson kütyüjét az Exchange szerverrel. (A szinkronizáció nem közvetlen, van egy erre a célra felingerelt Onebridge szerver a hálózaton. Ezt mi üzemeltetjük, de nem mi támogatjuk.)
A hibát kolléga bejelentette az alkalmazás támogatójának, akitől azt a választ kapta, hogy mentsük ki a postafiók tartalmát pst-be, töröljük a mailboxot, majd hozzuk újra létre – és ettől meg fog javulni a szinkronizáció. Sajnos a kolléga elhitte. Megkérte a középvezetőt, hogy másoljon ki mindent pst-be, majd amikor az jelezte, hogy oké, akkor törölt, purgált és újralétrehozott. A szinkronizáció természetesen nem javult meg, de ezzel a szállal a továbbiakban nem foglalkozunk.
A középvezető visszamásolta a cuccait – és reklamált, hogy valami nem stimmel, nem találja a kontaktjait. Egyeztetés után kiderült, nem tudta, hogy a Contact foldert is ki kellett volna másolnia. Legyünk már olyan kedvesek és állítsuk vissza az eredeti állapotot.
Ekkor jöttem be a képbe én és egyből elszürkült a tekintetem. Mentések természetesen vannak, de ez a purgált, majd újra létrehozott postafiók semmi jót nem ígért. A dumpsteren keresztüli visszaállítás természetesen szóba sem jöhetett.
Elsőkörben be kellett izzítani a Recovery Storage Group-ot az Exchange szerveren, felvenni a piszkálandó adatbázist. Gyors ellenőrzés a registryben: a HKLM\System\CCS\Services\MsexchangeIS\ParametersSystem kulcs alatt a Recovery SGOverride értéke nehogy 1 legyen, mert akkor a visszatöltés fejbevágja az eredeti adatbázist. Nyilván még helyet is kellett keresni a logoknak és az adatbázisnak, ennek megfelelően korrigálni az adatbázis adatlapját – és be kellett állítani, hogy az mentésből felülírható legyen.
Ennyit az előkészületekről, jöhetett a Tivoli Exchange kliens. Itt ért az első kellemetlen meglepetés: az aktív mentések sorából pont kicsúszott az a mentés, amelyre szükségem lett volna, az összes mentések listájának felolvasása meg jó másfél órába telt. Bejelöltem, hogy melyiket szeretném visszaállítani, aztán hagy szóljon.
Jó egy óra után, 99% körül elszállt a visszaállítás, miközben a szerver felsikított, hogy betelt a C:\. Amikor ennek a partíciónak a közelébe sem lett volna szabad mennie. Rövid bogarászás után megtaláltam, hogy a saját profilom verte ki a biztosítékot, simán felhízott 2,5 gigára. További bogarászás után azt is megtaláltam, hogy a Tivoli kliensben üres a temporary directory beállítás; a kis okos tehát a profilomba szemetelt. Kiganéztam, megadtam neki egy másik lemezt és újrakezdtem. Másfél óra a listáig, egy óra a visszatöltés.
Exchange sp1 óta a Recovery Storage Groupból elérhető a Mail Merge funkció (egyfajta lebutított Exmerge), ez nekem tökéletesen megfelelt. Kiválasztottam a másolás alfolderbe opciót és elmentem haza (1.5 GB; 20000 item).
Másnap leellenőriztem a kontaktokat: a folder üres volt. Miaszösz? Dismount, törlés, kezdjük újra az egészet. A másfél órás listavisszatöltés után megvizsgáltam a Tivoli klienst és azt találtam, hogy alapban be van kattintva az automatikus kijelölés opció. Tehát amikor kijelöltem a korábbi adatbázist, akkor ő a biztonság kedvéért végigjelölte a következő teljes mentésig a logokat is és persze a visszatöltés után rá is játszotta azokat – azaz visszakaptam egy olyan állapotot, amikor már az új postafiók volt az adatbázisban.
Kíváncsiságból kipróbáltam, mi történik, ha nem jelölök ki log visszatöltést és nem kérek rájátszást. Visszatöltés előtt figyelmeztetett, hogy lehet, hogy nem fogom tudni felmountolni az adatbázist. És milyen igaza volt: tényleg nem tudtam. Törlés, kezdjük előlről. Bejelöltem a megfelelő adatbázist, kikapcsoltam az automatikus kijelölést, bejelöltem az aznapi logokat (csak azokat!), kértem a rájátszást és beállítottam a temp directoryt.
Nna, így már sikerült.Ezt abból is észre lehetett venni, hogy ekkor már nem működött a Mail Merge. De még az Exmerge sem. Egyik sem találta a produkciós adatbázisban a recovery adatbázisbeli postafiók párját. Nyilván nem, mert ugye törölve lett, purgálva lett, sóval behintve lett. A felhasználóhoz rendelt postafiók már vadiúj volt, akkor is, ha minden látható név ugyanaz volt rajta. Nem kicsit frusztráló, hogy a kezelői felületen ott látom a mailboxot, de képtelenség kimenteni a tartalmát, mert minden eszköz merge műveletre van tervezve; ahhoz meg kell a régi postafiók. Pst-be másolás? Felejtsd el.
Iránya jó öreg google haver. Első körben itt van egy link; azt írják, hogy milyen állapotai vannak egy postafióknak és milyen állapotokban van esély visszaállításra. Purgálás után pl. semmi. Aztán a cikk végén felcsillantottak egy lehetőséget, megadtak egy másik cikket. Ennek már a címe is izgalmas volt, azt mondta: “Hogyan állítsunk vissza purgált postafiókot“. Átolvastam. Fejvakarás. Átolvastam még egyszer. Kezdtem érteni. Zseniális! Hogyan hekkeljük meg a Recovery Storage Group-ot? Először töltsük vissza az adatbázist az RSG-be, ahogyan kell, mountoljuk fel, majd azonnal le. Fontos, hogy ez simán történjen, érdemes a státuszt rögtön leellenőrizni az ’eseutil /mh’ paranccsal.
És itt jön a trükk: nevezzük át az adatbázis fájlokat, pakoljuk át máshová, csináljunk neki produkciós storage groupot, abba csináljunk neki adatbázist és mountoljuk fel.
Nem, nem kell a szívünkhöz kapni, nem lesz innentől kezdve mindenkinek két postaládája – ugyanis amikor felmountoltuk az adatbázist a Recovery Storage Groupban, akkor automatikusan minden postafiók lecsatolt állapotba került és ez a dismount során igy is maradt. (Mondjuk a zabszemteszten nem mentem volna át, amikor csatlakoztattam; mondtam már, hogy ez a VIP adatbázis volt?)
Most előreszaladtam egy kicsit, mert közben azért bejött a képbe a Nagy Harci Fasz.
Amikor ugyanis megértettem, hogy mit kell csinálnom, nekiálltam dismountolni az RSG adatbázist. Nem sikerült, a System Management konzol befagyott. Vártam másfél órát, majd kilőttem a Task Managerből. Kolléga összedugta fejét az ügyfél kapcsolattartójával, este hétkor engedélyezték a szerver újraindítását. Fél nyolckor jött a telefon, hogy gáz van, az Exchange szolgáltatások nem indultak újra. Fél nyolc után öt perccel jött az újabb telefon, hogy nagyobb gáz van, tkp. a szerver nem is állt le, csak úgy lebeg élet és halál között. Oké, irány a Dataplex. Érdekes látvány fogadott: a szerver működött, csak éppen a távoli elérést biztosító szolgáltatásai haltak el. Az egész leállási folyamat az Information Store leállására várt, az viszont beragadt ’stopping’ állapotba. Egyébként a szerver köszönte szépen, jól volt. Az eseménynaplót percenként szemetelte tele a System Attendant, hogy nem tud leállni, mert az Exchange szerver nem elérhető. Elég hülye kifogás. Megnéztem a Filemon cuccal, hogy egyáltalán mi történik: semmi különös, a store.exe egyfolytában a temp könyvtárat csesztette. Az adatbázisok viszont ott vigyorogtak lezáratlanul. Ezután dehogyis mertem kigyilkolni az IS-t. Ahogy a szakirodalom is mondja, ilyenkor kell felhívni a a Microsoft Premier Support-ot: hagy harapjanak ők is egy jó nagyot a felelősségből.
Tudom, minden rendszermérnök életében eljön az a pillanat, amikor éles szituációban be kell jelenteni telefonon egy hibát az amerikai PSS-nek. Ez, úgymond, egyfajta evolúciós lépcső. De nem hiszem, hogy mindenki annyit szerencsétlenkedik vele, mint amennyit én.
Ott kezdődött, hogy a szerverszobában 40-50 szerver duruzsolt a fülembe. Ki lehetett ugyan menni a folyosóra, de ott meg nagyon figyelni kellett a padlólapokat, mert tény, hogy bizonyos lapoknál elmegy a térerő. És persze a teljes kommunikáció egy pici mobillal történt.
Nos,én voltam annyira zöldfülű, hogy már rögtön az első hapinak nekiálltam magyarázni a technikai problémát, bőven ecsetelve az előzményeket. Kicsit ugyanis ideges voltam, mivel ez az ügyfél fő produkciós levelezőszervere volt, a kapcsolattartó pedig elnézte a dolgot, a cég legfontosabb projektjében ma kellett volna külföldre küldeni bizonyos záródokumentumokat.
(Ugyan javasoltam nekik, hogy küldjék el privát postafiókból webes felületen, de azt kaptam, hogy na ne már, verziókövetés van, előzmények vannak, subject kódok vannak, nekik válaszolni kell az előző levélre. Fóti Marci örökbecsűje jutott eszembe: ‘Az informatika még nem érte el azt a biztonsági szintet, hogy rábízzuk az életünket – de mi rábíztuk.‘)
Szóval egyáltalán nem lepődtem volna meg, ha megtudom, hogy az ügyfél verőemberei már melegítenek valahol.
Ehhez képest gyönyörűen elbeszéltünk egymás mellett: én állandóan a problémámat hajtogattam, a hapi meg állandóan azonosítgatni akart: Mi a cégem azonosítókódja? Mi az én azonosítókódom? Mit tudom én! – sikítoztam.
Végül javasoltam, hogy hagyjuk a fenébe az egészet, van hozzáférésem az Online Premier Support oldalhoz, majd bejelentem írásban. (Ott már valamikor hozzá lett rendelve a .net jelszómhoz az egész miskulancia.) Hát, az ötlet jó volt, de valamiért nem akart összejönni a belépés.
Végső kétségbeesésemben felhívtam a TAM-ot. Kolléga szerint nem koránfekvős fajta; Isten tartsa meg a szokását, ébren volt most is. Kikereste nekem a szükséges kódokat és elmagyarázta, hogy az első ember technikailag zokni, annak csak az a dolga, hogy beazonosítson. És azt is javasolta, hogy ha olyan helyen vagyok, ahonnan rosszul hallom a szöveget, kérjek Translation Service-t. Ingyenes és minden nyelvre meg van szervezve. Remek. Megkértem, hogy küldje el az adatokat az otthoni címemre, majd webfelületről leszedem. 10 percig vártam, nem jött semmi. Egy kicsit téptem a hajamat – tényleg csak egy kicsit, aztán valahogy összehegesztettem a céges OWA elérést – lassú is volt, bizonytalan is, de a miénk… és működött. Oda is megkértem a levelet és megjött.
(Másnap esett le: otthonról olyan gyorsan jöttem el, hogy bejelentkezve maradtam a gépemnél – és persze, az Outlook pop3-mal mindig lekapta a levelet. Elmehettem a búsba a webfelülettel.)
Mindegy, megtanultam a leckét: company id nélkül ma már sehová se megyek; itt fityeg a PDÁ-n.
Innentől kezdve már csak egy óra kellett, hogy eljussak a technikai emberhez. Mondjuk az idő nagy részét az tette ki, hogy vártuk a Translation Service-t, aki végül ezen a napon nem jelent meg.
A többi már viszonylag simán ment: elmondtam a problémát, a hapi elkérte az applikációs logot (16MB – bizonytalan OWÁ-n keresztül…), majd némi fejvakarás után közölte, hogy nincs más hátra, gyilkoljam ki a store.exe-t. Eddigis hülyén nézhettem ki – gondolom, a dataplexes fiúk jót szórakozhattak a monitorszobában, hogy percenként rohangászok ki a folyosóra (sorry, I’ll go out… please repeat it…), utána meg vissza a gépterembe, minden alkalommal beriasztva őket… de ezt a lépést már nem voltam hajlandó pusztán szóbeli utasításra meglépni. Megkértem a fazont, hogy írja le emailben, mert nem hallom jól, amit mond. Leírta, kigyilkoltam, újraindítottam és felállt minden. Mármint szolgáltatás. Mondjuk az alatt az öt perc alatt, amíg az IS húzta a csíkot, öregedtem egy kicsit: 8db adatbázis figyelt a gépen, összesen olyan 600 GB méretben. Ha az IS nem indult volna el egyből, akkor életem végéig mentésből kellett volna adatokat töltögetnem.
De elindult. Már csak azt kellett kinyomozni, mi a lószar volt ez? Délután is, amikor nekem beragadt a System Manager és este is, amikor a leállítás ragadt be, a víruskergető jegyzett be gyanús hibaüzeneteket a logba.
Ez egy hálás toposz, exchange adminok előszeretettel szeretnek mindent ráfogni a víruskergetőre – és nem is ok nélkül.
Csak a rend kedvéért, hogy mi mindent tud okozni egy rosszul beállított víruskereső:
-A fájl szintű víruskereső megfogja az exchange adatbázist. Information Store nem fér hozzá, kardjába dől.
-A fájl szintű víruskereső karanténba dobja a tranzakciós log egy-egy fájlját. Information Store kardjába dől, a rendszergazda szintén.
-Ilyenről is olvastam: ha nincs elzárva a fájl szintű kereső elől az exchange szintű kereső temporary könyvtára, akkor a fájlszintű kereső ráharap az ideiglenes állományokra és lefagyasztja az exchange víruskergetőt. Még jó, hogy egy cégnél dolgoznak a fiúk. Bár a cikkben büszkén írták, hogy az ő termékük egy ilyen crash után képes meggyógyítani magát, nem kell újratelepíteni.
Nos, lássuk csak, nálam mi történhetett. Visszatöltöttem mentésből az adatbázist,és… hoppá. Nem a szokott helyre töltöttem, mert ott nem volt elég hely – ehelyett egy másik partíción csináltam neki egy könyvtárat. Kitiltottam belőle a fájlszintű víruskergetőt? Bizony nem. Megint hoppá.
–Mekkora farok vagy, Joep – mormogtam hajnalban – ekkora potyagólt a te korodban már nem illik kapni.
És jobb későn, mint soha alapon bementem a víruskereső konfig menüjébe, ahol… meglepetten láttam, hogy az aranykezű kolléga korábban az egész partícióról kitiltotta a víruskeresőt. Tehát farok vagyok ugyan, de szerencsére megúsztam, nem én hibáztam.
(Mondjuk ekkor már voltam annyira fáradt, hogy a folyosón nekimentem az ajtónak: valamiért azt hittem, hogy ki fog nyílni magától. Pedig öreg dataplexes vagyok, pontosan tudom, mely ajtókat kell ballal húzni és melyeket jobbal tolni. Komolyan mondom, kész szerencse, hogy az ügyfél nem látja, hogy milyen állapotban hajt végre életveszélyes műtéteket időnként az üzemeltető.)
A magam részéről itt abba is hagytam a nyomozást egy ‘holnap is nap lesz‘ rikkantással.
Úgyis lett. Első lépésben kikapcsoltam a fájlszintű keresőt. Aztán megnéztem, hogy is áll az RSG adatbázis. Az eseutil szerint a státusz: Dirty shutdown. Hát, nem pont ez állt a cikkben. Adatbázis fájlok törlése, logok törlése, Tivoli. Másfélóra várás a listára, az egyetlen lehetséges kombináció összekattogtatása,visszatöltés. Aztán elindítottam egy Filemont, hogy lássam mi is történik mountolás/dismountolás közben. Semmi érdekes. A store.exe gyanúsan sokszor piszkálta a temp könyvtárat, mely nem volt kizárva a fájlszintű ellenőrzés alól. Kizártam. Az exchange szintű kereső ideiglenes könyvtárát is. Meg kiterjesztés alapján is kizártam az Exchange fájlokat, nemcsak könyvtárnév alapján.
Aztán megint net és kiderült, hogy teljesen rossz nyomon jártam: az az applikáció, mely teleszemetelte a logot a lefagyások előtt, az nem a fájlszintű víruskereső, hanem az exchange szintű. Itt dobtam egy négylábas megadást; összeszedtem a bizonyítékokat és elküldtem a feljelentést a gyártó képviselőjének.
Sokkal jobban izgatott, hogy mi lesz a középvezető kontakt listájával. Az újabb visszatöltés, mount/dismount után az RSG adatbázis státusza szépen Clean shutdown lett, tehát kezdődhetett a hekkelés.
Új, produkciós storage group létrehoz, adatbázis definiálódik. Természetesen másik könyvtárban, a biztonság kedvéért átnevezve. Utána adatbázis fizikailag is átmásolódik, átneveződik, nagy levegő, mount. Egyből jött is a hibaüzenet: adatbázis nem található. Kezdő exchange adminokra ilyenkor törhet rá az az érzés, hogy sürgősen keresni kell egy konnektort vizeletürítési céllal. Ne tegyétek. Sokkal praktikusabb odasétálni a pár méterre lévő darts táblához(1), leemelni a nyilakat és önfeledten hajigálni 10-15 percig. Ha esetleg átfúródik a táblán, nem gond, a fal azért megfogja. Ahogy eltelik az idő, az Active Directory csak szétreplikálja az egész hóbelevancot – és már mountolható is az adatbázis. És igen, mindegyik postafiók le volt csatolva. Nyertünk.
A doksi szerint meg kell keresni a diverzáns postafiókot és hozzávágni egy dummy felhasználóhoz. (Melyet természetesen megcsináltunk, miközben az AD replikációt vártuk.) Oké, dobjuk meg egy postafiókkal. (Sánta, van púpod? Nesze!)
Megint hibaüzenet jött: azt mondta, hogy az a legacyExchangeDN, mely ehhez a postafiókhoz tartozik, már másik felhasználóhoz van rendelve. Hja, mindenre mi sem gondolhattunk. Persze, könnyű a doksinak, ott nem feltételezték azt, hogy purgálás után rögtön újra létrehozzák az új postafiókot a régi felhasználóhoz.
Végülis, nem olyan nagy gond ez, a középvezető user adatainál átírtam AdsiEdittel a legacyExhangeDN értéket valami marhaságra, a recovery usernél átírtam a jóra, 10 perc darts és már csak be kellett pöckölni a labdát: a régi postafiókot hozzá tudtam rendelni a recovery userhez, megnyitottam outlookból mind a két postafiókot és átmásoltam azt a szájbanyomott kontakt listát a pacákhoz. Finita.
Persze még hátravolt a takarítás. El akartam tüntetni ezt a hibrid adatbázist, mert valahogy nem vagyok nyugodt, ha ilyenek kóricálnak a szerver körül. (Jártam már úgy, hogy törölt felhasználók valahogy megtalálták az RSG adatbázit és boldogan csatlakoztak hozzá.) Viszont az sem kizárt, hogy a hapi pár nap múlva veszi észre, hogy valami még kell neki. A tiszta munka átmozgatni a postafiókot egy létező adatbázisba, a hibridet meg lecsatolni, letörölni.
Másolás elindult. Az alkotó hátradőlt és várta, hogy besöpörje a hálás telefonhívások özönét. Ehelyett a helyi kolléga telefonált, hogy a középvezető igen zabos, mert fontos levelet vár, de semmilyen levelet nem kap meg; az összes levele valamilyen recovery usernél landol. Hoppá.
Elfelejtettem visszaírni másolás előtt a legacyExchangeDN értéket. Hát… most már meg kell várni a folyamat végét. 1,5 GB, 20000 item, 30 perc darts.
Az indikátor kijelzi a 100%-ot, majd a másolás könnyed sóhajtással befagy. Ez a szerver nem fér a bőrébe. Szerencsére ezen a területen már megszívtam az összes megszívnivalót, tudtam, mit kell tenni.
Hagy idézzek egy korábbi írásomból:
Végülmár csak ketten maradtunk a porondon: a 4.6 GB méretű mailbox és én. Szembenéztünk egymással, a szél ördögszekeret sodort keresztül az úton. Hirtelen mozdulattal rávetődtem a billentyűzetre és megismételtem a másolási parancsot – de most egy másik adatbázisba. Két óra szuttyogás után megint behalt a másolás… Task Manager, kilőni. Most már 3 példányban volt meg a mailbox – és mind a 3 működött. Egyszerre. Ha elvettem az egyiket a felhasználótól, mind felszabadult. Ha visszaakasztottam rá az egyiket, akkor a többit sem lehetett törölni, mert azt mondta, hogy használatban vannak. A helyzet kezdett kínossá válni. Végül kimentegettem az anyagot pst-kbe, lecsatoltam a mailboxot, töröltem a két rosszat, a maradékot visszacsatoltam – és gyönyörűen működött. Nem sokat dobott a kedvemen, hogy közben megtaláltam a helyes megoldást: a behalt mozgatást kilövés után folytatni kell _ugyanabba_ az adatbázisba, amelyikbe elkezdtük. Szószerint azt írták, hogy az Exchange van olyan intelligens, hogy észreveszi a sikertelen másolás darabjait. Usually. Hát… engedtessék meg nekem a kétkedés joga.
Nos, tulajdonképpen szerencsésnek tarthatom magam: lehetőségem volt kipróbálni, hogy milyen brilliáns hibajavító algoritmust tartalmaz a mailbox move folyamat arra az esetre, ha egy postafiók mozgatás 100% elérése után fagyott le. Tippelj.
Az nyert, aki arra voksolt, hogy nemes egyszerűséggel letörli a félbehagyott postafiókot és azt mondja, hogy kezdd újra, Gézám.
De legalább vissza tudtam állítani a legacyExchangeDN értéket. Újabb 10 perc darts és a középvezető megnyugodhatott: ő lett ő és megvolt a kontaktlista. Aztán végül nem töröltem semmit, lecsatoltam a recovery userről a postafiókot és dismountoltam az adatbázist.
Ősi cowboy szólás, hogy csak a dismountolt adatbázis a jó adatbázis.
Most már tényleg hátradőlhettem: megoldottam a lehetetlent, csak egy kicsit várni kellett rá. A kiajánlott (és kifizetett) 4-5 óra helyett 33-at.
Persze igazán nyugodt nem lehetek: kiváncsi vagyok, mikor veszi észre, hogy a Calendar is üres. Ekkor leszek igazán bajban: fogalmam sincs, hogyan lehet egy Calendarnak azt mondani, hogy select all, aztán copy másik mailbox. Hallottam már olyan emberről, aki látott olyan embert, akinek pst-n keresztül már sikerült ilyesmi – de arról is kiderült, hogy más volt.
(1) Ne mondd, hogy nincs. Nem lehetsz ennyire kezdő a szakmában.
Recent Comments