Az előző részekben szó esett a public folderek felépítéséről, részletesen leírtam egy egyszerű replikációs folyamatot és alaposan belementem abba, hogy milyen mechanizmusok támogatják az atombiztos multimaster replikációt.
Jelen írásban viszont inkább arra térnék ki, mi van akkor, ha valami mégsem működik annyira biztosan? A gyors válasz könnyű: akkor a replikáció betonbiztosan nem működik.
A legegyszerűbb megoldás, ha néhány konkrét eseten keresztül mutatom be ezt a nemműködést.
IV Tipikus problémák és megoldások
A címben első ránézésre van egy kis barokkos túlzás. A tipikus probléma ugyanis úgy néz ki, hogy nem működik a public folder replikáció. És itt meg is szokott állni a tudomány. Nem is csoda – a folyamat mélyebb ismerete nélkül az adminisztrátor leginkább csak hadonászik fakardjával a sötétben.
Nézzük, milyen eszközökre lesz szükségünk a megoldási folyamatban:
- Eventlog, applikációs log.
- Message tracking center.
- ADSIedit.
- ArchiveSink.
- Józan ész.
Különösen az utóbbi fontosságát nem győzöm hangsúlyozni. A többi simán megvásárolható a boltban – de a tiszta gondolkodás nem található egyik polcon sem. Nevelgetni kell.
Az első, józan észhez kötődő megjegyzés: mindig pontosan legyünk tisztában vele, hogy hol vagyunk. Multimaster replikációnál talán ez a legfontosabb kiindulási pont. Tudni kell, melyik szerveren változtatunk és mely szervereken várjuk, hogy a változás – a replikáció révén – megjelenjen. Az Exchange System Manager-ben állítható, hogy melyik Exchange szerveren lévő public foldert támadjuk be. (Connect to… opció)
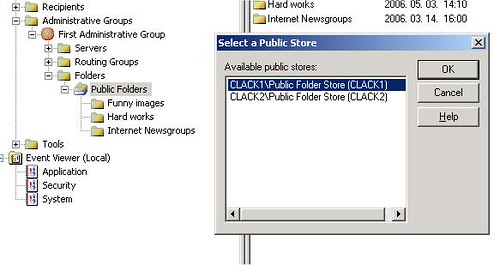
5. ábra A vizsgálandó Exchange szerver kiválasztása
Ha kliens oldalról piszkálódunk, akkor kiindulhatunk abból, hogy első körben azt a replikát fogjuk elérni, mely azon a szerveren van, ahol a postafiókunk. Amennyiben azon a szerveren pont nincs replika, akkor valószínűleg azt a szervert fogjuk elérni, amelyiken van replika és egy site-on van a postafiókunkat tartalmazó szerverrel. Habár létezik tool ennek pontos kiderítésére (MFCMAPI), de a használata nem nevezhető egyszerűnek. (Ez a segédeszköz az Information Store-ban tárolt paramétereit mutatja meg az egyes foldereknek. Jelen esetben a PR_REPLICA_SERVER paraméter tartalma érdekelhet minket.)
Ejtsünk még pár szót az applikációs logról. Alaphelyzetben az Exchange szerver nem túl bőbeszédű. Ha azt szeretnénk, hogy megeredjen a nyelve, fel kell emelni a logolás szintjét. Ezt megtehetjük a grafikus felületen vagy a registry-n keresztül. Nyilván van valami különbség a kettő között: a grafikus felületen beállítható maximum paraméter 5-ös erősséget takar, míg a registry-n keresztül beállíthatjuk az abszolút legerősebb logolási szintet, a 7-est.
Még azt kell eldöntenünk, melyik paraméteren állítsunk erősséget. Habár a Replication Errors paraméter nagyon illegeti magát, gyakorlati haszna nincs. Válasszuk helyette a Replication Incoming és a Replication Outgoing paramétereket; becsületszóra jobban járunk velük.
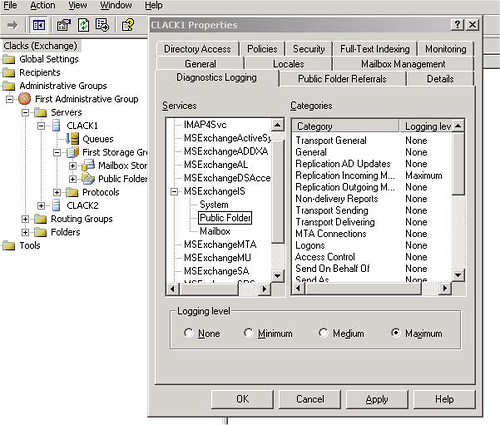
6. ábra Logolási erősség állítása grafikus felületről
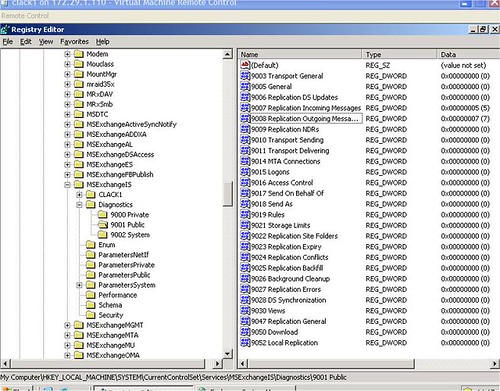
7. ábra Logolási erősség állítása a registry-ben
Érdemes megfigyelni, hogy a 6. ábrán bekattintott Maximum erősség a 7. ábra szerint egyáltalán nem a maximum.
És most akkor jöjjenek a tipikus problémák.
1 A szerver nem publikálja a változásokat
Szokásos alaphelyzet. Jön Béla és módosít egy nyilvános mappa elemet – mert Béla már csak ilyen. Csakhogy Jenőnél a változás nem jelenik meg.
Induljunk el a változás forrásától. Első körben nézzük meg, azon a szerveren, amelyen a módosítás történt, be van-e kapcsolva a public folder replikáció. (A replikáció időzítését a 4. ábrán látható panelen tudjuk megnézni.) Az ‘always run’ érték jelenti a 15 percet. A legtöbbször egyébként nem folder szinten szokták hangolni a replikációs időzítéseket, hanem store szinten.
Amennyiben be van kapcsolva, akkor emeljük fel az események logolási szintjét a korábban említett módon és változtassunk meg egy újabb elemet. Most jön 15 perc dartsozás. (Alternatívaként lehet a képernyőt is bámulni üveges szemmel.) Ha nem találunk az applikációs logban 0×4 vagy hierarchia változtatás esetén 0×2 bejegyzést, akkor gáz van – a szerver nem publikálja, hogy rajta változtatás történt. Nagy valószínűséggel a PFRA nem indult el – és ez bizony nagyon nem jó hír. Általában ez az eset mixed módú organizációkban fordul elő, ahol még vannak 5.5 szerverek is. (Egy ilyen esettel foglalkozik pl. a 272999 KB cikk.) Ugyanezt a jelenséget tapasztaljuk, ha az 5.5 – 2000/2003 rendszerek között nem működik megfelelően a legacyDN – SID konverzió. (Ilyen eset lehetséges, ha a konverzió során ugyanaz a SID generálódott le két különböző felhasználónak. Értelemszerűen, ezt manuálisan kell korrigálni.)
2 Tényleg a szükséges szervernek lett elküldve a replikációs csomag?
Folytassuk az előző esetet. Tegyük fel, hogy 15 percen belül megtaláltuk a 0×2/0×4 bejegyzést az applikációs logban – tehát a szerver elküldte a replikációs csomagot. Kérdés, hogy hová? Ugye az alap probléma, hogy Jenő szerverén nem látszik a változás – azaz a szerver nem kapja meg a csomagot. Ez klasszikus levéltovábbítási probléma – úgy is kell megoldani.
Ilyenkor vesszük elő a Message Tracking Centert. Jó tudni, hogy a replikációs üzeneteket a PFRA-k úgy küldözgetik egymásnak, hogy mind a feladó, mind a címzett az adott szerver Public Folder Store szolgáltatása. Ezek smtp címei pedig a következőképpen generálódnak: <servername>-IS@<domain.name>; azaz pl. Clack1-IS@cegnev.hu.
Mind a hiba oka, mind a konkrét megoldás sokféle lehet. Mindet nem áll szándékomban sorba venni, inkább leírok egy konkrét esetet a saját élményeimből. Clack1-n változtattunk public folder tartalmat, de a változás nem ment át Clack2-re. Applikációs log szerint a replikációs üzenet elment – és ugyanezt tapasztaltam a Message Tracking szerint is. Clack2 ennek ellenére már nem kapta meg a replikációs csomagot. Hirtelen ötlettől vezérelve elkezdtem másképp kérdezgetni a Message Tracking-et. Addig ugyanis úgy vizsgálódtam, hogy beírtam egy időintervallumot és ott látszott, hogy igen, az egyik IS elküldte a másiknak a levelet. Most beírtam a konkrét emailcímeket (lásd fent), és amikor a címzettére kerestem rá, akkor nem kaptam találatot.
Kis kitérő: az smtp cím érdekes állatfajta. A címzett címe szerepel egyfelől a borítékon, másfelől magában a levélben is. Az ‘okos’ levélmutogatók ezt a belső címet szokták mutatni, mondván, hogy ez való inkább emberi fogyasztásra. Sajnálatos módon a levéltovábbítás a borítékra írt cím alapján működik – legalábbis az első lépésben. (A reply… az egy más világ.)
Nos, ez történt itt is. A szép cím a levélben tényleg a távoli IS neve volt, de a borítékra nem került fel semmilyen cím sem – tehát a levelek elmentek a nagy fekete semmibe. Ez onnan derült ki, hogy elővettem az ADSIedit segédprogramot és megnéztem az Active Directory konfigurációs névterében, hogy a célzott szerver IS szolgáltatásán belül konkrétan mi a Public Folder Store smtp címe. Konkrétan üres volt.
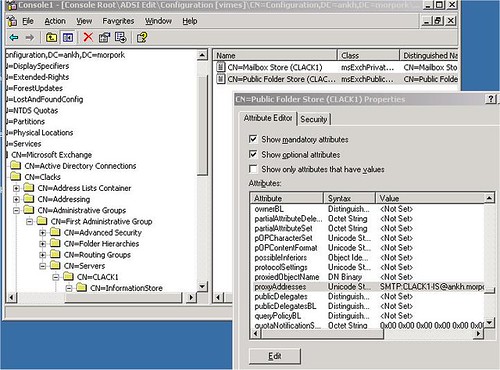
8. ábra Public Folder Store smtp címének tárolási helye a címtárban
Miután beírtam a megfelelő címet és megvártam, hogy szétreplikálódjon, beindult a public folder replikáció is.
3 Eljutott-e odáig a csomag?
Ha Clack1 elküldte a replikációs csomagot és ténylegesen Clack2 smtp címét írta bele, de ennek ellenére Clack2 mégsem kapta meg azt (nem szerepel az applikációs logjában a 0×2/0×4 üzenet), akkor ott levéltovábbítási problémával állunk szemben. Belépett a levélelkapó manó az organizációba. Ilyenkor segíthet a Message Tracking, az ArchiveSink segédprogram, illetve az egyes konnektorok és egyáltalán az email routolás átnézése. (Ez utóbbiról már írtam egyszer egy részletesebb cikket.)
4 A fogadó szerver megkapja a replikációs csomagot, de nem történik semmi.
Egyre cifrább, mi? Clack2 megkapta a replikációs csomagot – a Message Tracking szerint – de az applikációs logja nem mutat semmit. (Nyilván itt is maximálisra állítottuk a két paraméter logolási szintjét.) Ilyenkor mi van?
Alapvetően két eset lehetséges.
Elképzelhető, hogy a szerveren korrupttá vált a Replication State táblázat.
Gyors ismétlés: ez egy olyan táblázat, melyben a szerver adminisztrálja az egyes replikációs csomagokat. Minden replikabeli foldernek külön sora van.
Simán előfordulhat, hogy egy sor kiesik a táblázatból. Ekkor, hiába szerepel Clack1 replika listájában, hogy Clack2-n is van a konkrét foldernek replikája, és hiába látszik ugyanez Clack2-n is a grafikus felületen, Clack2 a Replication State tábla alapján úgy érzi, hogy nála bizony nincs – és lepergeti magáról a replikációs csomagokat. Gyógyítani lehet a klasszikus kiszáll-beszáll módszerrel: eltávolítjuk a folder replika listájáról Clack2-t, majd újra visszarakjuk.
Azért létezik ennél cizelláltabb megoldás is, az isinteg programnak van egy olyan kapcsolója, hogy replstate. (Egész konkrétan lásd a 889331 KB cikkben.)
Nézzük a másik esetet.
Exchange2003 esetében képbe kerülhet egy jogosultsági problémára visszavezethető hibaforrás is. Az Exchange2003 ugyanis igényli, hogy a feladó szervernek meglegyen a Send As joga a fogadó szerver virtuális SMTP szerverén. Ellenkező esetben a fogadó szerver nem fogja tudni lejátszani a replikációs csomagot. Alaphelyzetben ez a jogosultság adott… de a jogosultságok arról híresek, hogy az adminisztrátorok elállítgatják. (Nem feltétlenül kell persze semmit sem elállítani: elég, ha a feladó szerver kikerül az Exchange Domain Servers csoportból.) Hogy cifrázzam a helyzetet, olyasmi is előfordulhat, hogy habár a jogosultságok léteznek, de a fogadó szerver Kerberos hiba miatt képtelen autentikáltatni a feladó szervert.
5 Tudja-e a PFRA, hogy hiányzik adata?
Honnan is tudná az a szerver? Emlékszünk rá, egy konkrét folder teljes CNset-je a státusz üzenetekben utazik. Ha kimarad egy változás, akkor bizony a szerver egész addig nem értesül a változtatásról, amíg ugyanabban a folderben nem következik be egy másik változás. (Eltekintve azon ritka esetektől, amikor módosítjuk a replika listát vagy visszatöltünk mentésből egy régebbi állapotot – illetve el nem telik 24 óra a legutóbbi változás óta.)
Arra is emlékszünk, hogy a hiányzó változás rákerül a szerver kívánságlistájára, majd a timeout letelése után a szerver elküldi a backfill igényt. (0×8) A kívánságlistát közvetlenül nem tudjuk olvasni, de ha meredt szemmel figyeljük az applikációs logot, akkor észrevehetjük a 0×8 üzeneteket. Ha van ilyenünk, akkor biztosak lehetünk benne, hogy a PFRA tudja, hogy valami hiányzik.
A módszer egyetlen hátránya, hogy kicsit sokat kell várni. Ha például egy másik site-on van egyedül megfelelő replika, akkor az első timeout 12 óra, a második 24 és a harmadik 48 óra. Ennyi még dartsból is sok.
Le lehet egyszerűsíteni a szituációt úgy, hogy rákényszerítjük a szervert arra, hogy vegye tudomásul a hiányzó változást. Ehhez természetesen különböző módszerekkel státusz információkkal kell bombáznunk.
-
- A kijelölt szerver 0×20 (status request) csomagot küld a replikáknak.
- A kijelölt szerveren lenullázódik a backfill timeout.
- Egyik lehetőség, hogy elmegyünk egy másik szerverre és megváltoztatunk valamit az illető folderben. Ilyenkor a replikációs csomagba belekerül a folder státusz információja is, tehát a lazsáló szerver biztos megkapja a szükséges információkat.
- Van egy remekül eldugott opció, melynek segítségével kikényszeríthetjük a tartalom szinkronizálást.
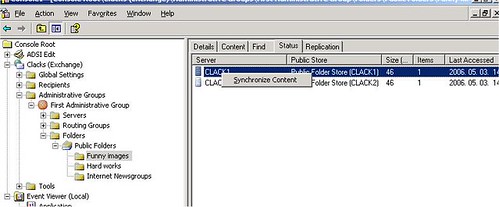
9. ábra Tartalomszinkronizálás kikényszerítése
Ha itt azt mondjuk egy folderen állva, hogy Synchronize Content, akkor két dolog történik:
Ebből az első a lényeges most számunkra: az egyik szerverről kiadott status request ugyanis mellékesen tartalmazza a szerver által ismert státusz információt is – nekünk pedig pont az a célunk, hogy a távoli szerverhez eljussanak ezek az információk.
Konkrétan: ha azt szeretnénk, hogy Clack2 megtudja, hogy nála hiányzik egy változás, akkor Clack1 megfelelő folderén kell megnyomni a Synchronize Content gombot. (És nagy ívben nem fog érdekelni minket, hogy Clack2 visszaküld majd egy 0×10 üzenetet.)
- Ugyanezt a trükköt tudjuk eljátszani a Send Hierarchy / Send Contents opciókkal is.
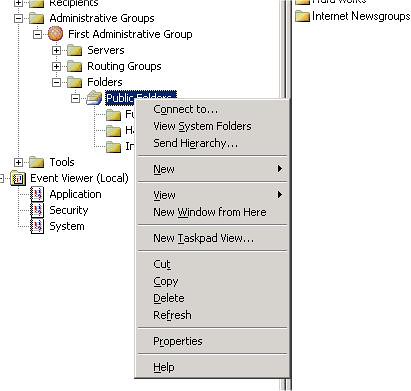
10. ábra Hierarchia replikáció kikényszerítése
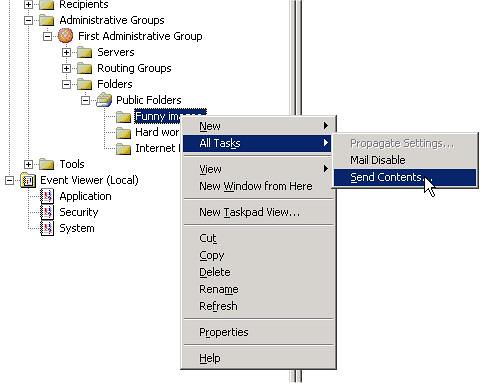
11. ábra Tartalom replikálásának kikényszerítése
Ekkor ugyan backfill válaszokkal küldjük meg a célzott szervert, de jelen esetben ez mindegy; az a lényeg, hogy az státusz információkhoz jusson, azok pedig a backfill válaszokban is benne vannak.
- Használhatjuk a korábban említett Replication Flag registry turkálást.
6 Ha tudja, akkor igényli is?
Miután jól kitömtük a szervert státusz információkkal, most már egész biztosan tudnia kell, hogy nem teljesen naprakészek a folderei. Kérdés, hogy ezután fog-e tenni valamit tudásbéli hiányosságainak leküzdésére?
Amit konkrétan szeretnénk látni, az az, hogy a szerver nekiáll a megfelelő replikákat tartalmazó szerverek felé 0×8 (backfill request) csomagokat küldeni. Ugyan várhatunk, hátha egyszer megjelenik az applikációs logban, de azért a timeout értékek meglehetősen ijesztőek. Jobb, ha akcióba lépünk. Az előző pontban szóba került egy módszer, a Synchronize Content. Megemlítettem, hogy ez mellékesen lenullázza a backfill timeout-ot is. Pont ez kell nekünk. Immár azon a szerveren, ahol hiányzik a tartalom, kiadunk egy Synchronize Content parancsot és egyből ki is kell menniük a 0×8 csomagoknak.
Mi van, ha mégsem mennek ki? Pontosabban valamerre kimennek, de pont a minket érintő csomagok nem jelennek meg? (Mi is érdekel minket? Van egy konkrét folder, amelyikben tudjuk, hogy nem frissül egy objektum. Tudjuk, hogy ennek mely szervereken vannak replikái – tehát szeretnénk olyan 0×8 csomagokat látni, melyek e replikák felé mennek és a kérdéses folder tartalmat igénylik.)
Ha ebbe az esetbe ütközünk, akkor jobb, ha tudjuk, hogy kivertük a biztosítékot. Van ugyanis egy ún. lassító mechanizmus a public folder replikációs folyamatban. (Én mondtam, hogy az Exchange fejlesztők nem kapkodó idegbetegek.) Ezt úgy hívják, hogy Outstanding Backfill Limit – és azt szabályozza, hogy a kívánságlista ne nőhessen a végtelenségig. Alaphelyzetben 50 elemet tartalmazhat. Természetesen ha egy backfill csomag beérkezett, akkor a PFRA kihúzza azt a listáról és bekerülhet helyére egy újabb. Viszont ha a szerver olyan csomagokat igényel, melyek már nincsenek meg egyik Exchange szerveren sem, vagy a szükséges Exchange szerver éppen elérhetetlen, akkor ez az ötven kívánság beragad és a többiek nem jutnak lehetőséghez.
Két dolgot tehetünk:
- Nekiállunk dolgozni. Megnézzük az applikációs logban, hogy hová mennek a 0×8 csomagok és mit igényelnek. Aztán megpróbáljuk elérhetővé tennük számukra a szükséges változtatásokat.
- Berugdossuk a dögöt az ágy alá. Registry piszkálással a fenti limit megnövelhető, egészen ötezerig. Ekkor viszont időszakonként komoly backfill viharokra számíthatunk, mely veszélybe sodorhatja az Exchange szerverek elérhetőségét.
7 Foglalkozik-e a többi szerver az igénnyel?
Az eddig leírtak alapján már nagyon könnyen nyomozhatunk. Láttuk, hogy az igénylő szerver elküldte a 0×8 backfill kéréseket.
Vizsgáljuk meg a megcélzott szerverek applikációs logját, hogy megkapták-e a csomagokat?
Ha megkapták, nézzük meg, válaszolnak-e rájuk. Ha igen, akkor azt kell látnunk, hogy megjelennek az applikációs logban a 0×80000002 illetve 0×80000004 backfill válasz üzenetek. (Értelemszerűen nem ugyanannyi válasz lesz, mint amennyi igény érkezett. Az igény azt mondja meg, hogy melyik változás kell neki. A válaszban meg megy a módosított elem – és ha a módosított elem nagyobb, mint a replikációs üzenet maximális engedélyezett mérete, akkor a PFRA több üzenetbe tördeli. Ugyanezért ne essünk kétségbe, ha a válasz nem egyből jelenik meg az igény fogadása után – elképzelhető, hogy sokat kell a csomag összeállításával bajlódnia a PFRA-nak.)
8 Megkapja-e a szerver az igényelt válaszokat?
Szinte már semmit nem kell írnom. A szokásos módon, az applikációs logok és a Message Tracking segítségével nyomon tudjuk követni, hogy mi történt a backfill válasz csomagokkal. Ha a szerver nem kapta meg, akkor levéltovábbítási problémánk van megint. Ha megkapta, de nem érvényesül a változás, akkor pedig a 4. pontban írtakkal állunk ismét szemben.
Nos, ennyi.
Remélhetőleg sikerült utat vágnom a dzsungelben.
Mi van még?
Az irodalom.
A cikk összeállításában sokat segített a Microsoft Technet Exchange szakkönyvtár és az Exchange csapat blogja. Mindkettő erősen ajánlott olvasmány.



{kind=link}
Recent Comments