_Nem_ csak azért ez a kedvenc témaköröm, mert a kajakomnak is ugyanez a neve. 🙂
A magam részéről tényleg ezt tartom az egyik legjelentősebb architekturális változásnak.
DAG: Database Availability Group. Azaz magas rendelkezésreállás, Exchange módra.
De beszéljünk előbb egy kicsit az Exchange 4.0-ról.
Abban ugyanis olyasmi van, ami az Exchange 2010-ben már nincs.
Storage Group.
Hogyan lett ez a szegény SG kegyvesztett? Bár pontosabb lenne a kérdés, hogy hogyan is lett ez ennyire kegyelt?
Tények jönnek.
- Egy merevlemezre a folyamatos írás sokkal-sokkal gyorsabb, mint a kevert írás/olvasás. Az írás ugyanis sorfolytonos, míg az olvasás véletlenszerű fejmozgással jár.
- A tranzakció alapú adatbáziskezelés során a logfájlokba gyakorlatilag folyamatos írás történik, minimális olvasással.
Tehát olyan helyeken, ahol alaposan megtervezték az Exchange környezetet és fektettek hangsúlyt a sebességoptimalizálásra is, ott célszerűen az adatbázisokat egy magas rendelkezésreállású diszktömbre tették, a tranzakciós logokat pedig – logonként – külön vincseszterre, illetve tükörre.
Hogyan is nézett volna ki ez konkrétan? Ahány adatbázis, annyi tranzakciós log, azaz annyi merevlemez. Annyi kártya vagy annyi LUN. Ráadásul ezek a logok nem igényeltek ám olyan nagy helyeket, miközben a vásárolható merevlemezek alsó kapacitása folyamatosan kúszott felfelé. És – bármennyire pitiánernek is tűnik első látásra – de az angol ABC betűinek a száma véges. 20 használható betűm van. (Ez mondjuk a 2007-esig még nem okozott gondot.)
A fentiek miatt találták ki a Storage Group fogalmát. Gyakorlatilag az történt, hogy több adatbázis kezelését vonták úgy össze, hogy egy tranzakciós log tartozzon hozzájuk. Ez már mehetett külön vincseszterre.
Az elv működött is szépen, egészen a 2007-es Exchange feltűnéséig. Ebben a termékben jelentek meg a különböző szines-szagos CR technológiák és kavarták meg rendesen az állóvizet. Mindegyik szép is jó is, hasznosak, praktikusak… csak éppen van egy apró hátulütőjük: csak akkor működnek, ha egy Storage Groupban egy, azaz maximum egy adatbázis található.
Az Exchange 2007-ben még volt annyi játékterünk, hogy eldönthettük, használunk-e CR-t, vagy sem. Bár sok érv nem szólt amellett, hogy ne használjunk, de még választhattunk.
Ezt a lehetőséget műtötték ki a 2010-ből. Függetlenül attól, hogy kell-e CR technológia – aka logshipping -vagy sem. Innentől már csak egy adatbázis lehet egy Storage Groupban. Így viszont nincs értelme magának az SG-nek sem… azaz kikukázták.
De nem csak ennyi történt. A hierarchia csökkenhetett volna úgyis egy szintet, hogy az adatbázisok továbbra is szerverekhez kötődnek – de ha már vágtak, akkor rendeset vágtak. Az adatbázisok a továbbiakban az organizációhoz kötődnek – azaz organizáció szinten kell egyedi névvel bírniuk -, a szervereken immár csak tartózkodási preferenciájuk lesz. Azaz amennyiben létrehozunk egy DAG-ot, akkor az abban szereplő adatbázisoknál adhatjuk meg, hogy a körbe bevont szerverek közül melyiken milyen preferenciával tartózkodjanak. (Értelemszerűen a DAG-on belül mindegyik adatbázis példányai között log shipping kapcsolat alakul ki.)
Anélkül, hogy elmerülnénk – egyelőre – a technikai mélységekbe, az elv megértése végett nézzünk most végig egy sorozatot.
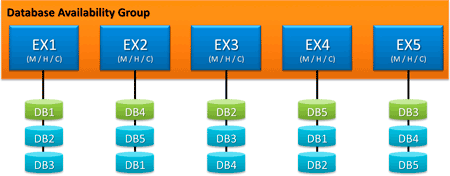
Létrehoztunk egy DAG-ot. Van hozzá öt szerverem, öt adatbázisom. Szerverenként három adatbázist kezelek. A prioritásokat a sorok jelentik, nyilván az első sor jelenti az aktív adatbázis példányokat.
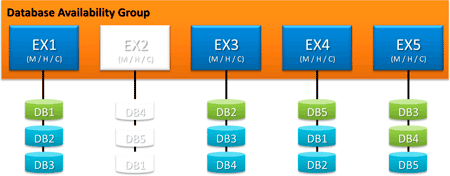
Patch kedd. Lekapcsoljuk a 2-es szervert, és vadul nekiállunk foltozni. Látható, hogy a DB4, mely korábban ezen a szerveren volt aktív, most az 5-ös szerverre mászott át. A DB5, DB1 adatbázisokkal nincs semmi dolgunk, azoknak továbbra is működik az aktív példányuk.
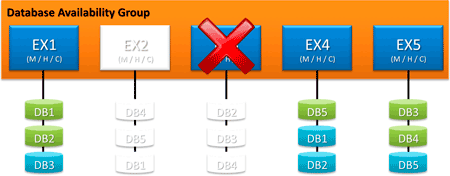
A takarítónő bevonul a szerverszobába és porszívózni akar. Kihúzza az egyik rack-et a konnektorból – és leáll a 3-as szerver is. Mit veszünk észre ebből? A DB2 immár az 1-es szerveren lett aktív, a DB3-nak és a DB4-nek még van aktív példánya. Igaz, a DB4-nek viszont már nincs passzív példánya.
A takarítónő pedig fütyürészve tolja a porszívó csövét.
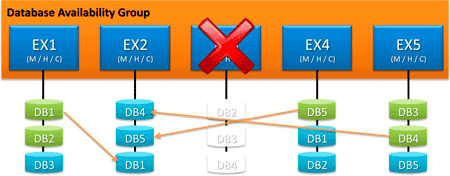
Befejeztük a hotfixek felrakását, visszaindítottuk a szervert. Az adatbázisok soványmalacvágtában tolják vissza a menetközben keletkezett logokat, majd ha ez megtörténik, a 2-es szerveren lévő DB4 aktívvá válik.
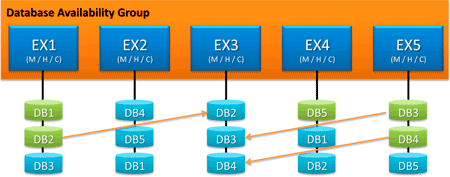
A takker is befejezte a munkát, visszadugja a rack konnektorát, a helyi emberünk megkapta a riasztást, kisétál, visszakapcsolja a szervert. Az előző fázishoz hasonlóan itt is beindul a logok másolása, egészen addig, amíg ki nem alakul a kavarások előtti helyzet.
Mit vettek ebből észre a felhasználók? Gyakorlatilag semmit. Mindig volt valahol aktív adatbázisuk. (Hogy a váltásokat hogyan vészelték át szakadás nélkül? Erre később fogok kitérni.)
Recent Comments