Az előző írásban ész nélkül beleszaladtunk a DAG-ba, pedig a magas rendelkezésreállással kapcsolatban nem csak erről van szó.
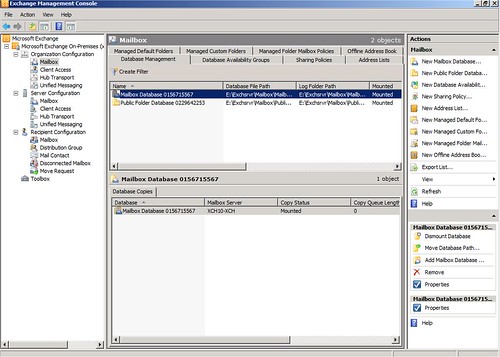
Nézzük meg ezt a képet. Érdekes módon mindkét középső panelen az adatbáziskezelés a téma. A jobb szélső akciópanalen láthatjuk is, hogy melyik panelen, miket lehet csinálni.
Vajon miért lett két panelre szétbontva a munka?
Azért, mert a felső panel az organizáció szinten egyedi adatbázisokat mutatja és itt az adatbázis paramétereit lehet állítgatni. Az alsó panelen viszont a másolat adatbázisok szerepelnek – itt a replikáció paramétereit láthatjuk, ha lekérjük a tulajdonságlapot.
És ami a legszebb az egészben, az az, hogy a felső panelen láthatjuk, most éppen a Database Management tabon belül vagyunk, a DAG… az egy egészen másik tab.
?
A helyzet az, hogy adatbázisokat tükrözni, log shippinget megvalósítani tudunk DAG nélkül is. Ezt a 2007-es verzióban úgy hívták, hogy Standby Cluster Replication: egy adatbázisról tetszőlegesen sok másolat létezhetett – és ha az aktív adatbázis megsérült, vagy a szervert líbiai terroristák felrobbantották, a rendszergazda aktivizálta az egyik passzív adatbázist és az élet ment tovább.
A DAG ennél több. A DAG a Cluster Continuous Replication örököse(1). A DAG az, aki tudja az automatikus átállást.
(1) Mind a Local Continuous Replication, mind a Single Copy Cluster némán kimúltak. Nem fértek bele a koncepcióba.
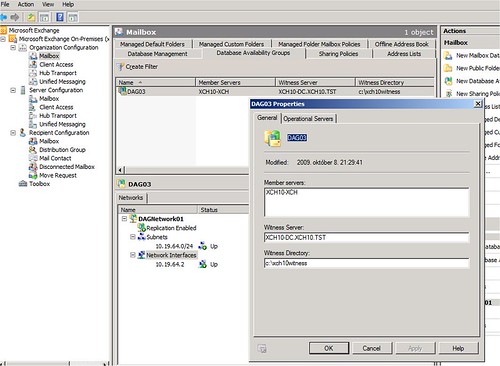
A képen egy csomó ismerős dolgot láthatunk: member servers, witness server, witness directory, network jellegű erőforrások. Mind-mind mutatja, hogy itt a háttérben – miután egy varázslóval gyorsan végigrohantunk a telepítésen – tulajdonképpen egy NFS tipusú failover cluster jött létre.
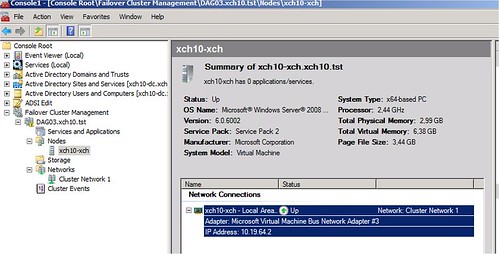
Olyannyira, hogy a DAG látszik a Failover Cluster Management konzolból is. Bár sasszemű kollégák kiszúrhatják, hogy ez nem az igazi CCR clusterre jellemző minta, sokkal inkább az ún. standby clusterre hasonlít. (A Services and Applications folder alatt nincs semmi, pedig ott kellene vigyorognia a CMS névnek, azaz a DAG nevének. Mely azért a DNS-be bekerült.)
Nézzünk végre konkrétumokat.
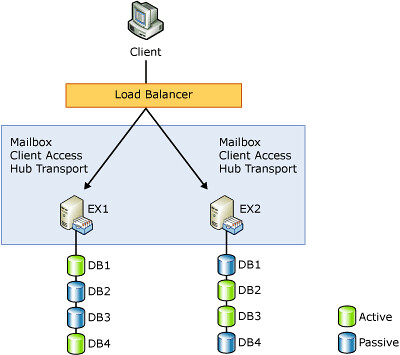
Az első képen egy viszonylag egyszerű DAG megvalósítást láthatunk. Két szerver – és minden megy rajta. Nem csak a Mailbox szerepkör fut rajtuk, hanem a CAS és HTS is. Korábban mi minden kellett a magas rendelkezésreállású szolgáltatáshoz? Két MBX szerver a CCR-hez, legalább egy CAS/HTS szerver a maradék Exchange funkciókhoz. 2 enterprise licensz, 1 standard. DAG esetében egy vas – licenszestől – kipottyant.
Nézzük meg jobban az ábrát. Vészcsengő kinél jelzett be? Fent a kliens, el akarja érni az adatbázis szervert… egy load balanceren keresztül?! Adatbázisszerver… NLBS mögött? Ordítóan durva hiba lenne… ha a kliens közvetlenül érné el az MBX szervereket. De az Exchange 2010 struktújában nem így megy. Stay Tuned.
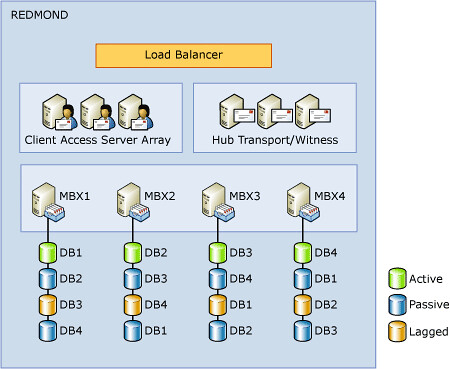
Ez már egy komolyabb DAG. Látható, hogy itt már leszedtük az MBX szerverekről a többi szerepkört, azok külön tömbben feszítenek az MBX szerverek előtt.
Két dolgot kell nagyon észrevenni az ábrán. Az egyik az MBX szerverek száma. Emlékszünk, CCR esetén két node volt. Snitt. SCR szervert akármennyit tehettünk mellé, de CCR-t nem. Ez a korlát immár a múlté – jelenleg 16 szerver a limit. A DAG-ban – hasonlóan a CCR-hez – nem feltétel, hogy a node-ok egy telephelyen legyenek. (Az egy Exchange organizáció viszont igen.) Egy hardverkövetelményt viszont kegyetlenül be kell tartani: a telephelyek közötti késleltetés nem lehet nagyobb 250 miliszekundumnál.
A másik: az aktív és passzív adatbázisok mellett feltűntek a Lagged adatbázisok is. Ez meg mi? Aki játszott már komolyabban SCR rendszerekkel, annak számára nem ismeretlen a fogalom. Ott ugyanis külön szabályozhatjuk, hogy a passzív adatbázisra mennyi kivárással (lag) játszódjon rá a log, illetve a rájátszás után mennyi idő múlva törlődjön fizikailag.
Mire is jó ez? Nos, nem árulok el nagy titkot, ha azt mondom, hogy az Exchange fiúk határozottan utálják a backup/restore eszközöket. Igyekeznek is bedobni minden trükköt, hogy kiváltsák ezeket. (Szvsz nem fog sikerülni.) A lagged adatbázis az egyik ilyen trükk. Amíg nem játszatom rá a logokat az adatbázisra, addig az az adatbázis a múltat mutatja. A maximális kivárás 14 nap. Tudom, most azt kérdezed, hogy és akkor mi van a dumpsterrel? Az is van. De. A dumpster a kuka. Ahová a törölt elemek kerülnek – és ahonnan azok egy bizonyos ideig még előbányászhatóak. (Jut eszembe, kuka ügyben is történtek komoly előrelépések.) De mi van, ha nem törlés jellegű adatmódosítás történt? Teszem azt, Vezérigazgató Árpád vett a lengyel piacon egy kínai e-book readert és amikor összeszinkronizálta az Exchange szerverrel, akkor felülírta az összes kontakját mandarin karakterekkel? Törlés nem történt, kritikus adatmódosítás igen. Ilyenkor jöhet a talonban őrizgetett lagged adatbázis.
Foglaljuk össze, akkor HA téren mik is a fejlemények:
- Nem kell drága hardver. Nincs szükség közös háttértárolóra, nincs szükség SAN-ra. Bele kell lapátolni egy jó nagy kupac merevlemezt a gépbe (JBOD) vagy hozzákapcsolni egy diszktornyot (DAS), oszt jól van. Sima SATA2-es lemezek is bőven megteszik.
- Olcsó elemekből, a mennyiség növelésével érünk el nagy megbízhatóságot. Ez az álmoskönyv szerint is jó skálázhatóságot jelent.
- A redundancia adatbázis szinten szabályozható.
- Tulajdonképpen az SCR/CCR rendszerek kombinációit használjuk, úgy, hogy a részletekkel nem kell foglalkoznunk(2).
(2) Tudom, te is olyan vagy, aki szeret a részletekkel foglalkozni. De nem mindenki ilyen.
2009-10-26 at 21:54
Az adatbiztonságról szólva: Szentgyörgyi Tibor technetes cikkében olvastam, hogy “szükségtelen biztonsági mentést készíteni, mert itt adat nem veszhet el”, ami, lássuk be elég bátor kijelentés, még a Microsoft részéről is. Persze a fent vázolt elképzelésben legalább három helyen létezhet az adat egyidőben, ami adhat némi biztonságérzetet, de a backup rendszerek készítői egyelőre nem fognak csődbe menni — már csak a berögzült attitűdök miatt sem.
——————
Közben eszembe jutott, hogy mennyit nyűglődtem személy szerint magam is az Exch2007 mentésével Win2008-on. Nem lehet, hogy az (név szerint hogy abban a környezetben nem lehet adatbázis szinten menteni az Exchange-t) már előfutára volt a mostani filozófiának?
2009-10-26 at 22:36
A backupless configuration, mint elérendő cél már a 2007-es terméknél is elhangzott Redmondban. (Akkora ordítozás is lett belőle, hogy nem győztem kapkodni a fejemet.)
Szvsz még álomként sem szabad komolyan venni. A backup az egy ultimate megoldás. Ahogy Hofi mondta, a sebész az igen. Azt mondja: levágtam. És tényleg. Ugyanez igaz a backupra is. Elmentettem. Kint van szalagon. Innentől bármi történhet, van egy konkrét időpontra vonatkozó állapotom.
Nyilván jó, ha bizonyos forgatókönyveket le tudok kezelni backup nélkül is. A 2010-es dumpsterre már olvastam kifejezetten vad ajánlásokat is. (Pl. 90 nap.) A lag is védhet módosítás ellen 14 napig. Az adatbázismásolatok tökéletesek katasztrófa utáni visszaállításhoz. Az archive mailbox segíti a személyes anyagok hosszútávú archiválását. A biztonsági másolatok tárolására megoldás a full journaling. Ha jól olvastam (ebben azért nem vagyok biztos), akkor már az SCR esetében is a sikeres logshipping triggereli a logtörlést az aktív példánynál, tehát ehhez sem kell backup. Szóval dolgoznak a fiúk az elimináláson, teszik el láb alól szorgalmasan a problémás eseteket. De mindent nem lehet. Egész egyszerűen nincs olyan, hogy minden lehetőséget számba lehessen venni. Ha egy cég évekre visszamenőleg szeretné, ha meglenne számára az időutazás lehetősége, ha a törölt levelek visszaállítási szkópja nagyobb, mint fél év – még mindig a backup a legegyszerűbb, legolcsóbb megoldás.