Takarítottam a sufniban és a kezembe akadt egy 10 mbites HUB. Először elmosolyodtam, aztán elérzékenyültem: Istenem, amikor ilyenekből építettük a hálózatot… a gyerekek alsósok voltak, nekem pedig még volt hajam…
Majd jött a következő gondolat: megőrizzem? Menjen a lomtalanításra szánt cuccok közé?
Nos, kidobásról szó sem lehet. Jó lesz ez még valamire.
1. Belehallgatni a hálózati forgalomba
Képzeld el, hogy van egy router az internet felé, a belső hálón pedig egy NAS. Egyik sincs rootolva (mert egyáltalán nem vagyok olyan vadember, mint amilyennek néha látszom), az utóbbin valami linux klón alapú oprendszer van. A NAS-on beállítható, hogy küldjön emailben riasztást, ha bármi rendkivüli esemény történt. Beállítottam. Van mellette egy ‘teszt’ gomb. Megnyomtam. Szűkszavú üzenet: a levélküldés sikertelen.
?
Ha látnám a hálózati forgalmat, sokkal okosabb lennék. De egyik eszközön sincs sniffer, a switchelt hálózatban meg cseszhetem a promiszkusz módot. Nos, ekkor jön a jó öreg HUB. Beledugom a NAS-t, beledugom a laptopot, beledugom a routert, és már indulhat is a Wireshark.
2. Kici ócó NLB
Nem lesz rövid. Ahhoz, hogy érthető legyen a levezetés, kénytelen leszek alaposan kivesézni ezt az egész NLB katyvaszt, közben persze el is fogok kalandozni jobbra-balra. De nem lesz minden haszon nélkül az írás, legalábbis remélem.
Kezdjük ott, hogy milyen NLB technikák is léteznek?
Multicast és Unicast.
Mindkét módszernél azt kell valahogy megoldanunk, hogy habár egy csomagot csak egy unicast IP címre küldünk el, az mégis több géphez érkezhessen meg. Sőt, az a varázsló, aki ezt elvégzi, gondoskodjon arról is, hogy a célgépek közötti terhelés elosztása konfigurálható legyen. Még sőtebb, tudjuk szabályozni azt is, hogy a szétszórás csak bizonyos portok között történjen meg.
A varázslót hívják NLB-nek, illetve a Windows implementációját WNLB-nek.
2.1 Multicast
Ebben az esetben az NLB node-ok hálózati kártyái kapnak egy plusz unicast IP címet (VIP) és egy plusz multicast MAC címet (VMACM), a meglévő unicast IP címük (IP1/IP2) és MAC címük (MAC1/MAC2) mellé.
A node-ok személyes adatforgalmát a módosítás nem érinti. Használják az IP1/2 és MAC1/2 címeket, élnek, mint Marci Hevesen. A switchben is a MAC1/2 címek jelennek meg, hiszen ez szerepel a csomagok Ethernet keretében. A VIP címet felvettük a DNS-be, kihirdettük a cégnél. Jön is a kliens és rá akar csatlakozni az NLB szolgáltatására. (Az egyszerűség kedvéért legyen ez egy weblap, de bármi más is lehet, ami egy tcp porton keresztül érhető el.) A felhasználó beírja a böngészőbe a címet, a DNS visszaadja neki a VIP-et, a gép elküld egy ARP kérést a VIP címre. Ez broadcast, tehát mindenki felkapja. Az NLB magára ismer és küld egy ARP választ, benne a VMACM címmel. A kliens örül, megvan a cél MAC address, beteszi az Ethernet keretbe, megy a csomag. A switch érzékeli, hogy a csomag címzettje egy multicast MAC cím, alaphelyzetben ezeket gondolkodás nélkül kitolja mindegyik portra, tehát a csomag megérkezik az NLB-hez is, aki a saját szeszélye alapján továbbtolja valamelyik node-ra.
Okos? Okos. Működik? Háát…
Akadnak bajok.
Például egy másik kliens a router mögül próbálkozik. Ilyenkor a túloldali ARP kérést a router ragadja magához, hogy majd ő küld egy újabb ARP kérést a másik alhálózaton. Elküldi, visszakap egy olyan kombinációt, miszerint a cél node-nak unicast IP címe és multicast MAC címe van. – Ne te, már ne! – hőköl vissza és eldobja a csomagot. Kommunikáció meglőve. Ezt még kilőhetjük úgy, hogy a router ARP táblájába felvesszük statikus bejegyzésként a VIP-VMACM párost, ilyenkor nincs ARP kérdezz/felelek, a router helyből tudja a MAC címet, tehát mehet a csomag. (Hozzáteszem, hogy vannak olyan háklis routerek, melyek nem csak az ARP válaszban nem bírják elviselni a unicast IP – multicast MAC kombinációt, hanem úgy egyáltalán sem. Ekkor elfelejthetjük a Multicast NLB-t, vagy érdemei elismerése mellett nyugdíjazzuk a routert.)
Oké, router rendben. De mi van, ha az NLB akar küldeni egy csomagot a nyúlon routeren túlra? Kezdi azzal, hogy küld egy ARP kérést a router IP címére. Windows 2003-ig bezárólag az NLB csalt, mert az ARP kérést a MAC1/2 címről küldte, de a Windows 2008 már a VMACM címet teszi a kérésbe. Mit csinál ezzel a router? Úgy van, kidobja oda, ahová a szabálytalan csomagokat szokta. A kommunikáció megint meghalt. Kénytelenek leszünk az NLB node-ok ARP tábláját is módosítani, fel kell venni a router IP-MAC párosát statikus bejegyzésként. Ekkor nem kell megvárnunk, hogy a router válaszoljon a szabálytalan kérésünkre, menni fog a feloldás séróból is.
És még nincs vége a galibáknak.
Mit is írtam? A switchre küldött multicast MAC címet tartalmazó csomagot a switch alapból kiküldi minden portjára. Jó ez nekünk? Nem annyira. Gyakorlatilag elárasztjuk a switchre kötött egyéb hostokat tök felesleges csomagokkal. (Úgy is hívják a jelenséget, hogy flood.) Természetesen ez ellen is lehet védekezni, de itt már elgondolkodik a rendszergazda arról, hogy mennyire is igaz a Microsoft azon állítása, hogy az NLB olcsó és egyszerű technika.
Az egyik megoldás úgy néz ki, hogy okos switchünk van, ahol be tudjuk állítani, hogy a multicast csomagok mely portokon jelenhetnek csak meg. A többi port coki. Ez működik, de olyan nem elegáns. Ha figyelmetlenül valamiért átdugom másik portba az NLB lábát, akkor újra floodolok, ráadásul lehet, hogy csak akkor veszem észre, amikor vezig ordítva beront a gépterembe a hálózat lassúsága miatt. (Oké, jobb helyeken a vezig kártyája nem nyitja a gépterem ajtaját, de nem biztos, hogy adott esetben ez a hosszútávú megoldás.)
Sokkal elegánsabb, ha még okosabb switchet használunk, mely már tudja az IGMP snooping technikát. Ekkor persze az NLB-t is konfigurálni kell. Azt mondjuk neki, hogy az ARP válasz csomag mellé tegyen már egy IGMP Host Membership Report csomagot is. Erre a csomagokra általában csak a routerek vevők, de nekünk okos switchünk van, aki bele tud lesni (snoop) az IGMP csomagba, és innentől tudni fogja, hogy mely portok mögött van olyan host, amelyik multicast vevő. A többire nem küldi tovább a multicast MAC címmel rendelkező csomagokat.
Végül természetesen megoldás lehet az is, hogy az NLB két lábát külön VLAN-ba tesszük. Ekkor ugyan a csomagok továbbra is elárasztják a broadcast domaint (a switchnek azokat a portjait, melyek a VLAN-hoz tartoznak), de mivel csak a két NLB láb érintett, így a floodolást az érintett portokra korlátoztuk. Viszont gondoskodnunk kell a VLAN elérhetőségéről.
Nos, ennyi. Látható, hogy a megoldáshoz módosítani kell mind a router, mind a node-ok ARP tábláját és minimum menedzselhető switchekre van szükségünk, akár portot akarunk konfigurálni, akár VLAN-t akarunk kialakítani, az IGMP snoopingról már nem is beszélve. Ez bizony se nem kici, se nem ócó. (A moddolt firmware-es olcsó routereket most hanyagoljuk.)
2.2 Unicast
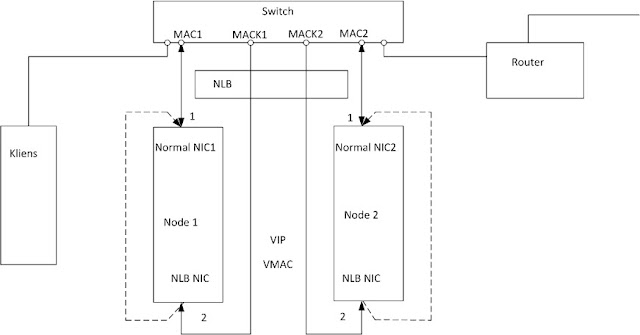
Ennél az NLB technikánál más a trükk. Az NLB lecseréli a node-ok címeit, egy közös VIP és VMAC címre. Mindkettő unicast, tehát semmi szükség a multicast-os trükközésekre. Mivel mind a két node címei megyegyeznek, a nekik küldött csomagok megérkeznek az NLB-hez, aki már tud velük játszani.
Nyilván ez sem ennyire egyszerű. Például milyen MAC címet jegyez be a switch a node-ok portjaihoz? A VMAC-et? Azzal gond lesz, mert az elsőt be fogja jegyezni, a másodikat már nem, mivel ugyanaz a MAC nem jelenhet meg más porton is. Ezzel jól ki is heréltük az NLB-t, mert mindig csak egy portra menne a forgalom.
A trükk az, hogy NLB elmaszkolja a VMAC címet. Összedob mindkét node számára egy kamu MAC címet és ezt teszi az Ethernet keretbe. (Az ábrán MACK1 és MACK2.) A switch ezeket a címeket fogja bejegyezni a portokhoz.
Nézzük akkor a folyamatot. VIP-et bejegyeztük, kihirdettük, felhasználónk beírja a böngészőbe, a gépe elküld egy ARP kérést a VIP címre. Az NLB felkapja, belerakja az ARP keretbe a valódi VMAC értéket. (Az Ethernet keretben a kamu MAC cím van, de ez jelenleg senkit nem érdekel.) A kérdező megkapja, boldog. Összedobja a csomagot. Hogyan? Hát belerakja a frissen kapott VMAC értéket az Ethernet keretbe. Elküldi. Mit fog ezzel a csomaggal csinálni a switch? Hát, zavarba jön. Ilyen MAC cím nincs hozzárendelve egyik porthoz sem. Ilyenkor a standard eljárás az, hogy a switch kiküldi a csomagot minden portra és reménykedik abban, hogy valahonnan visszajön egy válasz és akkor majd bejegyzi jól. Hát, ezt most várhatja.
Lássuk a cifrázást.
A router jelen esetben nem háklis. Mind a VIP, mind a VMAC normális unicast címek. Suhannak a csomagok, mint olajos hal a vécélefolyóban.
Ellenben. Tud-e kommunikálni a két node egymással? Nézzük. Node1 küld egy ARP kérést a VIP címre. Az ARP keretben visszakapja a VMAC értéket. Ezt belerakja a küldendő csomag Ethernet keretébe… majd döbbenten észleli, hogy ez az ő MAC címe. Nem küldi sehova.
Legalábbis nem mindig. És nem mindet.
Ott van például az NLB heartbeat. Erről annyit kell tudni, hogy broadcast, az Ethertype értéke 0x886F és csak node szinten működik, azaz azt nem tudja megállapítani, hogy a port szabályokban megadott portokon tényleg fut-e valami szolgáltatás. Na, ez a kommunikáció például megy. Miért is? Hiszen mondtam: broadcast. Csak a célzott kommunikáció nem megy.
És az se mindig döglődik. Windows 2003 Sp1 óta pl van egy érdekes lehetőség. A registry-ben engedélyezhető (UnicastInterHostCommSupport) hálózati kártya szinten, hogy unicast node-ok is tudjanak egymással beszélgetni.
Ettől függetlenül ez a modell nem terjedt el. Gondoljunk bele, mit csinálnánk, ha rendszergazdaként be szeretnénk lépni konkrétan az egyik node-ra? Az NLB meg mindig a másikra dob. Idegbaj. Emiatt is szoktak berakni az NLB kártya mellé egy másik hálózati kártyát.
Nem mondanám, hogy egyszerűsödik, mi? Számok, szaggatott nyilak, minden, ami szem-szájnak ingere.
Az alapprobléma az, hogy melyik kártyán legyen beállítva a default gateway. Mindkettőn nem javasolt, mint ahogy a Windows erre figyelmeztet is. Na jó, akkor melyik legyen a nagy hatótávolságú, routeren is átlátó kártya és melyik az, amelyik csak a subneten beszélget? Hülye kérdés. Nem így fogjuk rendezni a helyzetet. Egyszerűen beállítjuk a normál kártyát első számú kártyának (erre kerül a default gateway), az NLB kártyát meg második számúnak. Így bármelyik kártyán is jön be csomag, kifelé a normál kártyán fog menni.
Ha hagyják.
A Vista/Windows Server 2008 vonulat óta a hálózati kártyák összelinkelése alaphelyzetben tiltott. Azaz ha az NLB kártyán jön be egy csomag, akkor az nem tud kimenni a másik kártyán. Ehhez netsh segítségével rá kell linkelni az NLB kártya forgalmát a normál kártyára. Ekkor már ki tud menni.
Windows Server 2008 esetén ugyanezt másképpen is el tudjuk érni. Modellváltás. A Windows Server 2008 alaphelyzetben az ún. Strong Host modellt használja. A korábbi szervertermékek a Weak Host modellt alkalmazták, mely azt jelenti, hogy az operációs rendszernek semmi kifogása sincs az ellen, hogy multihomed (több hálókártyás) rendszerben az egyik kártyán keresztül el lehessen érni a másik kártyán futó szolgáltatásokat. A mi esetünkben ez azzal jár, hogy a Windowst át kell váltani a Weak Host modellre. Naná, ezt is netsh-val, méghozzá kártyaszinten, azon belül is külön küldő, illetve külön fogadó irányban.
Zsong már a fejed? Pedig még nincs vége.
Nézzük át, mi is történik ilyenkor. VIP publikálva, felhasználó gépétől jön az ARP kérés a VIP címre. Ez broadcast, kimegy mindenhová, az NLB felkapja. A válaszba belerakja a VIP és a VMAC értékeket. A visszamenő csomag viszont már a konkrét gép valós hálózati kártyáján megy ki, annak a MAC címe kerül bele az Ethernet keretbe… de ez megint senkit nem érdekel. A túloldalon kicsomagolják az ARP keretet, a következő csomag Ethernet keretébe már az onnan jövő MAC (VMAC) kerül, ez kikerül minden switch portra (mert ismeretlen), az NLB felkapja, a válaszcsomag megint a normál kártyáról megy ki… és így tovább.
Akkor most gondoljuk végig, mi a helyzet flood téren?
Hát, ugye, van. Éppen az előbb jártuk körbe.
Védekezési lehetőség? Nos, az IGMP itt nem játszik, hiszen nincs multicast. Emiatt a switch portját sem tudjuk multicastra konfigurálni. Bizony, egyedül a VLAN felosztás segít, azaz megint drága, menedzselhető switch kell.
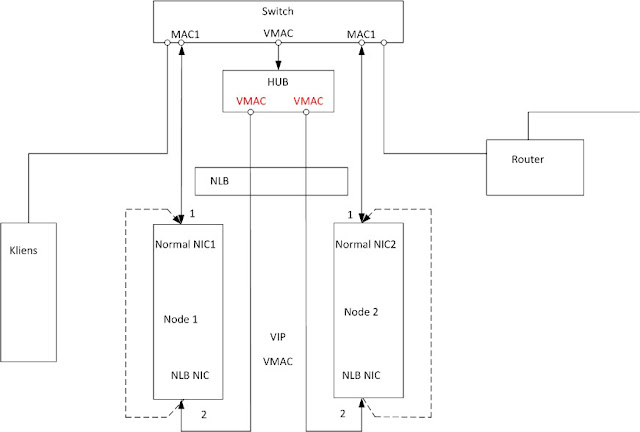
És ez az a pont, ahol az eddig csendben üldögélő HUB végre szerepet kap.
Mi az a csoda, amit a HUB tud? Hát az, hogy nagyjából akkor élte a fénykorát, amikor az NLB-t kitalálták. Erősebbet mondok: az NLB-t a HUB-hoz találták ki, ez az eszköz az NLB ideális játszótere. Miért? Mert a HUB abszolút nem foglalkozik a MAC címekkel. Nem azon a szinten dolgozik. Nagy ívben tojik arra, hogy mit bűvészkedünk a keretekben az L2 címzésekkel. Ez majd a később elszaporodó és egyre okosabb switchek problémája lesz.
Nézzük meg, mit is csináltunk. Az NLB hálókártyákat nem közvetlenül dugtuk be a switchbe, hanem beraktunk eléjük egy HUB-ot. Ennek már csak egy uplinkje kerül bele a switchbe. Mennyi? Egy.
Járjuk körbe ismét a folyamatot. A switch portjára két MAC is rákerül, a kamu MACK1 és a MACK2. A kliens elindít egy ARP kérést, ez broadcast, kikerül a HUB-ra, az NLB felkapja. Valamelyik normál hálókártyáról válaszol, az ARP keretben a VMAC. Kliens következő csomagjában az Ethernet keretben a VMAC, beérkezik a switchbe… ahol megint nem lesz ilyen MAC egyik portnál sem, tehát megint floodolunk.
Izé. Nem maradt itt ki valami?
Dehogyisnem.
A switchben most már csak egy helyen jelenne meg a VMAC, tehát nincs szükség maszkolásra. Egyszerűen kikapcsoljuk: MaskSourceMac érték nullára állítása a registryben. Ekkor kapjuk a fenti ábrán látható szituációt. A HUB letojja, hogy két lábán is ugyanaz a MAC – a VMAC – jelenik meg. Hiszen nála meg se jelenik, nem érzékeli. (Ezért piros.) Az uplinken – függetlenül attól, hogy melyik node-tól jött – csak a VMAC jelenik meg, tehát ez kerül rá a portra. A kliens ARP kérésére az NLB válaszol. Maszkolás nincs, tehát mind az Ethernet, mind az ARP keretbe a VMAC kerül. (De az Ethernet keret még mindig nem érdekli a klienst. A switchet annál inkább.) A kliens a VMAC címre küldi az újabb csomagot, a switchen van ilyen MAC a portoknál, tehát flood kilőve, a csomag csak a HUB-ra jut ki.
Nézzük meg, mit csináltunk. Van egy borzasztó gagyi, nem menedzselhető switchünk és egy, a sufniból előkukázott HUB. Mindösszesen egy plusz kábelbe, illetve egy registry állításba került és tökéletesen működő NLB megoldásunk van.
Tényleg jó néha az öreg a háznál.
Ps1.
Felvetődhet, hogy jó-jó, de mi a helyzet a sebességgel? A switch már jó eséllyel gigás. Hogyan lesz ezzel összhangban a 10 mbites HUB? Melyik piacon lehet venni gigás HUB-ot? A helyzet nem ennyire rossz. Nézzük csak meg, hogyan forognak a csomagok. A szerverre – konkrétan az NLB kártyára – küldött csomagok tényleg keresztülmennek a HUB-on, de a szerverről a kliens felé menő forgalom már közvetlenül a switchre megy. Legtöbbször a kliens csak vezérlő utasítást küld a szerver felé, az pedig adathalmazokat tol vissza – azaz a HUB pont ott szűk keresztmetszet, ahol egyébként sem nagyok az igények.
Ps2.
A cikknek ezzel még nincs vége. Az első célt elértük, látjuk, hogy a HUB-ot tényleg tudjuk még mire használni. De a téma még nincs körbejárva: mi a helyzet például a virtuális környezettel?









Recent Comments